Datensatzsammlung aus Geisteswissenschaften
| Anna Klaas |
|---|
| RWTH Aachen University |
| anna.klaas@rwth-aachen.de |
Inhaltsverzeichnis
- Vorwort
- Geschichte
- Literatur
- Musik
- Film - Star Wars Network
- Zusammenfassung
- Links zu den Quelldaten
- Referenzen
Vorwort
Auf dieser Seite des Online Buches werden einige Datensätze aus den Geisteswissenschaften vorgestellt. Bei der Suche nach den Datensätzen wurden unterschiedliche Open-Source-Plattformen wie Kaggle, Wolfram Data Repository, Center for Computational Analysis of Social and Organizational Systems (CASOS), KONECT – The Koblenz Network Collection und The Correlates of War Project genutzt.
Diese Sammlung dient als Unterstützung für den Einstieg in die Arbeit mit WebOCD. WebOCD ist ein webbasiertes Open-Source-Framework für die Entwicklung und Analyse von Algorithmen zur Erkennung von überlappenden Communities. Es ermöglicht den Nutzern, Daten zu importieren, verschiedene Algorithmen darauf anzuwenden und die Ergebnisse graphisch darzustellen. (Shahriari et al., 2015) Die Datensatzsammlung soll aufzeigen, dass das WebOCD nicht nur in Computerwissenschaften, sondern in anderen unterschiedlichen Forschungsbereichen, darunter auch Geisteswissenschaften, eingesetzt werden kann.
Die Sammlung ist in drei Kategorien unterteilt: Geschichte, Literatur, Musik und enthält zusätzlich den Datensatz zu den Filmdrehbüchern der Episoden I-VI der Star Wars Filmreihe. Die Datensätze wurden im WebOCD importiert, darauf wurden unterschiedliche Algorithmen zur Erkennung der überlappenden Communities angewandt. In den meisten Fällen wurden die Default-Parameter für die Algorithmen genutzt, andernfalls werden die Werte angegeben. Bei Bedarf wurden die Datensätze vor dem Import bearbeitet und/oder in ein anderes Format überführt. Die dabei entstandenen Visualisierungen sind auf dieser Seite vorgestellt. Die Knoten sind in Farben der jeweiligen Communities eingefärbt, überlappende Communities können an der Vermischung der Farben erkannt werden.
Die Links zu den ursprünglichen Datensätzen werden unter “Links zu den Quelldaten” angegeben. Die angepassten Datensätze können zusammen mit ihren Visualisierungen auf Github gefunden und für eigene Tests weitergenutzt werden.
Geschichte
Colonial/Dependency Contiguity
Datensatz
Der Datensatz “Colonial/Dependency Contiguity” (Correlates of War Project. Colonial Contiguity Data, 1816-2016. Version 3.1., n.d.) umfasst alle Kontiguitätsbeziehungen zwischen Staaten im internationalen System von 1816 bis 2016 durch ihre Kolonien oder Schutzgebiete. Das heißt, wenn zwei Kolonien zweier Staaten aneinander grenzen oder wenn ein Staat an eine Kolonie eines anderen angrenzt, wird im Datensatz eine Kontiguitätsbeziehung zwischen den beiden Hauptstaaten eingetragen. Die Daten haben das CSV-Format. In diesem Format werden die Werte durch Kommas getrennt. Die Verlinkungen sind ungerichtet, um Assymetrien zu vermeiden. Bei bestimmten Staat-Staat-Paaren können mehrere verschiedene Kolonial-/Schutzgebietbeziehungen aufgeführt sein, wenn einer oder beide Staaten mehrere Kolonien/Schutzgebiete haben. In diesen Fällen werden separate dyadische Beziehungen für jede Interaktion zwischen Staaten/Schutzgebieten erstellt. Die Daten wurden für den WebOCD-Import vorbereitet und in das GML-Format konvertiert. Die Kontiguitätsdatensätze wurden von Paul Hensel, University of North Texas, im Rahmen des COW Data Hosting Program erstellt.
Visualisierung
Auf den Datensatz wurde der Fuzzy C Means Spectral Clustering Algorithmus angewandt. Dabei ist folgende Visualisierung entstanden und 5 Communities erkannt worden. Die Staaten mit den meisten Kolonien und Schutzgebieten bilden eine große Community (gelb). Dies lässt sich dadurch erklären, dass sie und ihre Kolonien/Schutzgebiete viele Grenzen gemeinsam haben und somit stark miteinander verbunden sind. Zu solchen Staaten gehören Vereinigtes Königreich, Frankreich, die Niederlande, Spanien und Portugal. Das sind auch diejenige Staaten, die zu den Kolonialzeiten die meisten Kolonien hatten, dadurch ist die Vielzahl der Verbindungen entstanden.
Florentine Families
Datensatz
Der Datensatz beschreibt die sozialen Beziehungen zwischen florentinischen Familien der Renaissance, die von John Padgett
aus historischen Dokumenten erfasst wurden. Das Netzwerk hat zwei Layer: familiäre Beziehungen (Eheschließungen zwischen
den Familien) und finanzielle Geschäftsbeziehungen.
Inhaltlich umfassen die Daten Familien, die um das Jahr 1430 in einen Kampf um die politische Kontrolle der Stadt Florenz verwickelt
waren. In diesem Kampf dominierten zwei Fraktionen: die eine drehte sich um die berüchtigten Medici, die andere um die
mächtigen Strozzi. (Padgett & Ansell, 1993)
Visualisierung
Der Datensatz enthält eine Txt-Datei mit der Knotenliste und eine Datei im Edges-Format mit der Kantenliste für die beiden Layer des Netzwerks. Die Daten wurden angepasst: die Knoten und die Kanten sind in einer Datei im Unweighted Edge List Format zusammengeführt worden, die Layer sind in zwei separate Dateien aufgeteilt worden. Auf die Daten wurde der Speaker Listener Label Propagation Algorithmus angewandt. Für die Eheschließungen ist die folgende Visualisierung entstanden.
Die Visualisierung bestätigt die Aussage aus der Beschreibung des Datensatzes: Medici und Strozzi sind die einflussreichsten florentischen Familien und bilden verschiedene Communities. Für die Geschäftsbeziehungen ist die folgende Visualisierung entstanden.
Hier sieht es ganz anders aus, die Familie Strozzi ist in dem Netzwerk nicht dargestellt. Die Community, die der Medici gegengesetzt wird, wird von der Familie Lambertes gebildet. In dem Eheschließungennetzwerk ist die Familie nicht so stark dargestellt. Daraus kann man schließen, dass diese Familie sich mehr im Geschäft eingesetzt und außerhalb der konkurrierenden Familien Ehen geschlossen hat.
Territorial Change, 1816-2018
Datensatz
Der Datensatz “Territorial Change”(Tir et al., 1998) beschreibt alle territorialen Veränderungen zwischen Staaten in den Jahren 1816-2018. Es umfasst Eroberungen, Annexionen, Abtretungen und Sezessionen, aber auch Wiedervereinigungen. Der Datensatz zu den territorialen Veränderungen wird von Steven Miller, Clemson University, im Rahmen des COW Data Hosting Program gehostet. Der ursprüngliche Datensatz liegt im CSV-Format vor und enthält solche Informationen wie Jahr und Monat, Verlierer und Gewinner, Art der Veränderung für beide Seiten, ID der ausgetauschten Einheit, Fläche der ausgetauschten Einheit in Quadratkilometern, Einwohnerzahl der ausgetauschten Einheit usw.
Vorbereitungen
Der Datensatz enthält viele Informationen, die im WebOCD keinen Gebrauch finden und den Netzwerkimport unmöglich machen würden. Um ein Netzwerk aufbauen zu können, reichen die beteiligten Staaten, die als Knoten fungieren, und die Kanten zwischen je zwei Staaten, wenn ein Staat das Territorium von einem anderen Staat erobert oder annektiert. Zuerst wurden alle überflüssigen Informationen entfernt und die Daten in das Unweighted Edge List Format überführt. Der Datensatz enthält keine Labels, sondern nur Identifikationsnummern der jeweiligen Staaten. Damit die Visualisierung lesbarer wird, mussten die Namen zumindest von den bedeutendsten Staaten im Netzwerk hinzugefügt werden.
Visualisierung
Nach den oben genannten Anpassungen konnte das Netzwerk im WebOCD importiert werden. Darauf wurde der Speaker Listener Label Propagation Algorithmus angewandt, der 41 Communities erkannt hat. Wie es sich vermuten lässt, werden die Communities um die Staaten gebildet, die die meisten Kolonien hatten und/oder aggressive Geopolitik geführt und andere Länder erobert oder deren Gebiete annektiert haben. Zu solchen gehören auf einer Seite Großbritanien und Frankreich, die viele Kolonien gehabt haben, auf der anderen Seite Sowjetunion/Russland und Deutschland/Preußen, die bei beiden Weltkriegen auch vor und danach zu Veränderungen auf der Weltkarte geführt haben. Anhand der Visualisierung können ziemlich gut die Interessensgebiete und Einflusszonen von bestimmten Staaten abgelesen werden. Die Ländercodes können der Dokumenation des “The Correlates of War” Projekts entnommen werden.
Literatur
David Copperfield
Datensatz
Wie der Name schon sagt, bezieht sich der Datensatz auf den Roman “David Cooperfield” von Charles Dickens. Der Datensatz wurde von M. Newman (Newman, Mark E. J., 2006) konstruiert. Zum Aufbau wurden 60 am häufigsten vorkommenden Substantive und 60 am häufigsten vorkommenden Adjektive aus dem Buch genutzt. Die Begrenzung der Wörteranzahl dient nur der Übersichtlichkeit. Die Analyse kann auch auf ein viel größeres Netzwerk erweitert werden. Die Knoten des Netzwerks stellen die Wörter dar, zwei Wörter werden miteinander durch eine Kante verbunden, wenn sie an einer Stelle im Buch nebeneinander stehen. Acht der ausgesuchten Wörter werden im Buch nicht miteinander kombiniert, so wurden diese aus dem Datensatz entfernt. Somit umfasst der Datensatz 112 Knoten und 425 Kanten. Die Datei hat das GML-Format, so dass das Netzwerk ohne weitere Vorbereitungen im WebOCD importiert werden kann.
Visualisierung
Auf den Datensatz ist der Signed Probabilistic Mixture Algorithmus angewandt worden. Intuitiv sollte der Algorithmus zwei Communities erkennen: Substantive und Adjektive. So wurde der communityCount-Parameter bei der Anwendung des Algorithmus gleich 2 gesetzt. Die meisten Kanten stellen eine Verbindung zwischen Substantiv-Adjektiv-Knotenpaaren dar. Da im Englischen aber Adjektive zusammen mit anderen Adjektiven und Substantive zusammen mit den anderen Substantiven (the big green bus, the big tour bus) genutzt werden können, sind diese Communities nicht disjunkt und weisen Elemente auf, die zu beiden Communities gehören, so kommt es bei der Visualisierung zu der Vermischung der Farben.
George R. R. Martin’s “A Song of Ice and Fire”
Datensatz
Charakter-Interaktions-Netzwerk für George R. R. Martins “Das Lied von Eis und Feuer”-Saga ist im öffentlichen Zugriff auf Github verfügbar. Zwei Charaktere sind immer dann miteinander verbunden, wenn ihre Namen (oder Spitznamen) innerhalb von 15 Wörtern in einem der fünf Bücher von “Das Lied von Eis und Feuer” vorkommen. Das ist ein gewichtetes Netzwerk. Das Kantengewicht entspricht der Anzahl der Interaktionen je zwei Charaktere. Das Netzwerk umfasst 506 Charaktere und 1329 Verbindungen zwischen ihnen. Auf Github ist eine CSV-Datei mit der Liste von Verbindungen zwischen Charakteren verfügbar. Mit Hilfe von einigen Excel-Funktionen kann die Datei ohne viel Aufwand in das Weighted Edge List Format konvertiert werden, das im WebOCD als Importformat akzeptiert wird. Das ursprüngliche Netzwerk sieht nach dem Import im WebOCD wie folgt aus:
Visualisierung
Auf den Datensatz wurde der Neighborhood-Inflated Seed Expansion Algorithmus angewandt. Dabei ist folgende Visualisierung mit 11 Communities entstanden:
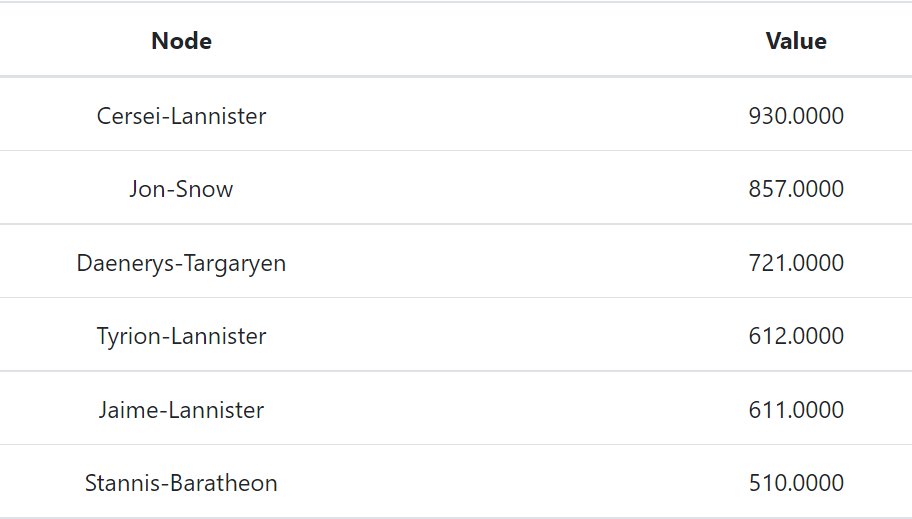
Anhand der Visualisierung kann man sagen, dass Jon Snow und Cersei Lannister die Hauptcharaktere sind, die am häufigsten erwähnt werden und die meisten Verbindungen zu den anderen Charakteren bilden. Die anderen Charaktere, die auch eine große Anzahl an Kanten haben, sind Daenerys Targaryen, Jaimie und Tyrion Lannister gefolgt von Stannis Baratheon. Es fällt auch auf, dass es mehr Verbindungen zwischen den Knoten innerhalb Communities gibt. So wird zum Beispiel eine Community mit Daenerys Targaryen, wo die meisten Communitymitglieder nur über Daenerys Verbidungen zu den anderen Figuren der Bücher haben. Die Figuren mit mehr Interaktionen gehören zu mehreren Communities gleichzeitig, was nochmal bestätigt, dass sie zu den Protagonisten gehören.
Die Aussage bezüglich Hauptcharaktere lässt sich auch durch Gradberechnung im WebOCD bestätigen. Die Knoten mit dem höchsten Grad haben die meisten Kanten und die meisten Interaktionen mit den anderen Bücherfiguren und sind somit plotbildend.
Es ist zu beachten, dass der genutzte Datensatz auf der Basis der Bücher entstanden ist und das Netzwerk sich von dem Netzwerk auf der Basis der Serie unterscheiden kann.
Les Miserables
Datensatz
Les Misérables ist ein Roman von Victor Hugo, der von dem Leben der französischen Gesellschaft zu der Napoleons Zeit bis zu der des Bürgerkönigs Louis Philippe schildert. Der Les Miserables Datensatz wurde 1993 von D.E.Knuth erstellt. (Knuth, 1994) Der Datensatz umfasst 77 Knoten und 254 Kanten. Die Knoten stehen für die Figuren, wie sie in den Knotenbeschriftungen angegeben sind, und die Kanten verbinden alle Figurenpaare, die im selben Kapitel des Buches vorkommen. Der Datensatz ist im XML- oder GML-Formaten vorhanden, so dass die Daten direkt im WebOCD importiert werden können.
Visualisierung
Das Netzwerk von Les Miserables Charakteren sieht ursprünglich wie folgt aus:
Auf den Datensatz wurde der Speaker Listener Label Propagation Algorithmus angewandt. Dabei wurden 8 Communities erkannt und es ist folgende Visualisierung entstanden:
Die Visualisierung hebt die Hauptcharaktere hervor. Es fällt direkt auf, dass Valjean die zentrale Figur des Romans ist, alle anderen Figuren sind irgendwie mit ihm verbunden. Am engsten ist Valjean mit Inspektor Javert, dem Antagonisten in dem Roman, verknüpft. Ein anderer Charakter, der viele Verlinkungen hat und somit eine eigene Community bildet, dennoch keine zentrale Figur ist, ist Gavroche. Es gibt Communities, die von den Figuren gebildet werden, die nur über einen anderen Charakter mit dem ganzen Netzwerk verbunden sind: so die rote Community über Myriel oder die violette über Tholomyes und Fantine. Die Figuren innerhalb dieser Communities interagieren nur mit den Figuren, über die sie verknüpft sind, und sind kein Teil der anderen Handlungsstränge.
Das WebOCD bietet an dieser Stelle eine schnelle und effektive Methode, um die allgemeine Struktur des Romans zu verstehen. Obwohl die Visualisierung den eigentlichen Inhalt des Buches benötigt, um einen Sinn zu ergeben, dient eine solche Darstellung als guter visueller Anreiz, der die Aufmerksamkeit auf sich zieht.
Literature 1976
Datensatz
Dieses Netzwerk enthält eine Reihe von niederländischen Autoren und Kritikern aus dem Jahr 1976. Die Knoten stellen Autoren und Kritiker dar. Eine Kante verbindet zwei Personen, wenn ein Kritiker in einer Rezension oder einem Interview literarisches Urteil zum Werk eines Autors veröffentlicht hat. Das Ziel der Ersteller von dem Datensatz war, mit Hilfe von der Netzwerkanalyse die Gruppenstrukturen in der Literaturkritik zu untersuchen. (Nooy, 1999) Der Datensatz umfasst 33 Personen und 80 Verbindungen zwischen ihnen.
Visualisierung
Auf den Datensatz wurde der Speaker Listener Label Propagation Algorithmus angewandt, der 4 Communities erkannt hat. Um Ergebnisse der Community-Erkennung besser interpretieren zu können, ist ein Verständnis davon notwendig, um wen es in dem Datensatz geht. Nach einer kurzen Recherche konnte es festgestellt werden, dass der Datensatz einige Fehler enthält, so sind vermutlich aus dem Namen eines Autors Arie B. Hiddema drei Knoten entstanden: Arie, B., Hiddema. Die Ersteller des Datensatzes teilen die Autoren und Kritiker im ursprünglichen Paper in drei Gruppen auf: die erste Gruppe beinhaltet Matsier, Hotz und Van Marissing, die zweite Luijters, Nuis, Mulder, Mertens und die dritte die restlichen Autoren und Kritiker. (Nooy, 1999) In dem verfügbaren Datensatz sind nicht alle dieser Namen vorhanden, jedoch hat der Algorithmus vier Communities erkannt, was den Ergebnissen von den Autoren des Datensatzes nah liegt. Es lässt sich vermuten, dass die Knoten falsch beschriftet worden sind. Die Visualisierung ohne Knotenbeschriftungen macht an dieser Stelle mehr Sinn. Es lässt sich schließen, dass das Ergebnis der Community-Erkennung stark von der Qualität der genutzten Daten abhängt. Enthält der Datensatz Fehler, so ist die Community-Erkennung ebenfalls ungenau und kann zu bestimmten Irrtümern führen. So ist es wichtig, die Datensätze selbst zu erstellen oder vor der Anwendung sie auf Fehler zu überprüfen.
Marvel Universe Comics
Datensatz
Das Netzwerk von Marvel-Figuren wurde von Pablo M. Gleiser von Buenos Aires Institute of Technology 2007 konstruiert. (Gleiser, 2007) Zwei Charaktere sind miteinander verbunden, wenn sie zusammen in einem Comics-Buch vorkommen. Das Netzwerk enthält 165 Knoten und 600 Kanten. Der Datensatz kann auf der Webseite von Center for Computational Analysis of Social and Organizational Systems (CASOS) heruntergeladen werden.
Der Datensatz liegt im XML-Format vor. Das WebOCD unterstützt unter anderem XML-Dateien als Import, diese müssen aber eine vorgegebene Struktur haben und bestimmte Attribute enthalten. Da der Datensatz diese Voraussetzungen nicht erfüllt, wurden die Daten in das GML-Format konvertiert und anschließend im WebOCD importiert.
Visualisierung
Auf den Datensatz wurde der Speaker Listener Label Propagation Algorithmus angewandt. Dabei wurden 48 Communities erkannt und es ist folgende Visualisierung entstanden:
Captain America, Iron Man, Spiderman und Thor sind die Figuren, die am häufigsten vorkommen und die meisten Verlinkungen haben. Spiderman-Community hat nur wenige Überschneidungen mit den anderen Charakteren, das lässt sich dadurch erklären, dass Spiderman 2007 kein Teil von dem Avengers-Team war. Auch die Fantastische Vier mit Mr. Fantastic, Human Torch, The Thing, Invisible Woman und X-Men mit Wolverine, Storm, Collossus, Night Crawler und Shadow Cat als Hauptcharaktere haben keine Überschneidungen mit Avengers, sind ziemlich isoliert und bilden eigene Communities. Außerdem fallen die kleinen Communities, die von dem restlichen Netzwerk komplett isoliert sind, auf. Zu solchen gehört zum Beispiel die Community zu der Comics-Reihe Shang-Chi (hellblau), das bedeutet, dass zu den Zeiten, als der Datensatz entstanden ist, es keine Interaktionen zwischen Figuren dieses Comics und anderen Figuren der Marvel Universe gab.
Musik
Jazz Musicians
Datensatz
Anhand einer Datenbank von Jazzaufnahmen wurde das Kollaborationsnetzwerk der Jazzmusiker von Pablo Gleiser und Leon Danon erstellt. In dem vorgestellten Netzwerk sind zwei Personen miteinander verbunden, wenn sie in einer Band gespielt haben. Die Analyse der Gemeinschaftsstruktur zeigt, dass diese Konstruktion wesentliche Bestandteile der sozialen Interaktionen zwischen Jazzmusikern erfassen. Laut Ersteller des Datensatzes können Korrelationen zwischen Aufnahmeorten, rassischer Segregation und der Gemeinschaftsstruktur beobachtet werden. (Gleiser & Danon, 2003) Der Datensatz liegt im .net-Format vor und enthält eine Auflistung von Knoten mit Beschriftungen und Kanten.
Vorbereitungen
Der ursprüngliche Datensatz umfasst 1286 Knoten und über 85000 Kanten. Darauf wurde der Speaker Listener Label Propagation Algorithmus angewandt und es wurden 45 Communities erkannt. Das Ergebnis ist auf dem folgenden Bild vorgestellt:

Da das Netzwerk so viele Elemente enthält, bleibt die Visualisierung unübersichtlich und kann im Browser flüssig nicht dargestellt werden. Es wurde ein Python-Skript geschrieben, um die Anzahl der Elemente zu verringern. Man kann die untere und die obere Schranke für den Knotengrad eingeben. Das Skript behält nur die Knoten, die einen passenden Grad haben, und konvertiert die Eingabedatei in das GML-Format.
import re
filename = input("enter file name\n")
minDegree = int(input("enter the minimum degree\n"))
maxDegree = int(input("enter the maximum degree\n"))
lines = []
elements = []
resMap = {}
result = ''
with open(filename) as f:
fileRead = f.read()
lines = fileRead.split('\n')
elements = re.split('[\\t\\n]', fileRead)
elementsMap = {}
for element in elements:
value = elementsMap.get(element, 0)
value += 1
elementsMap[element] = value
for line in lines:
if '\t' in line:
left, right = line.replace('\n', '').split('\t')
leftcount, rightcount = (elementsMap.get(left, 0), elementsMap.get(right, 0))
if ((leftcount > minDegree and leftcount < maxDegree) and ((rightcount > minDegree and rightcount < maxDegree) or rightcount == 1)):
value = resMap.get(left, [])
value += [right]
resMap[left] = value
result += 'graph\n[\n'
for key, values in resMap.items():
if len(values) > 1:
result += 'node [ id ' + key + ' label ' + values[0].replace('*', '"') + ' ]\n'
for key, values in resMap.items():
if len(values) > 1:
for value in values[1:]:
result += 'edge [ source ' + key + ' target ' + value + ' ]\n'
result += ']'
f = open(filename.replace('txt', 'gml'), "w")
f.writelines(result)
f.closeDaraus ist zum Beispiel die folgende Visualisierung entstanden. Dabei werden nur die Knoten mit dem Grad größer als 30 und kleiner als 200 berücksichtigt.
Es ist ersichtlich, dass Jazz Musiker bestimmte Gruppen, in denen Mitglieder eng miteinander verbunden sind, bilden. Es fällt die Community auf, die mit dem restlichen Netzwerk nicht verbunden ist (orange). Nach einer kurzen Recherche konnte es herausgefunden werden, was die Gemeinsamkeit ist, die die Mitglieder dieser Community miteinander verbindet. Alle diese Musikanten haben in einer der Louis Armstrongs Bands gespielt. So, wie früher bereits erwähnt, sind Wissen von dem Thema eines Datensatzes notwendig, um die Ergebnisse der Communityerkennung besser interpretieren zu können.
Hollywood Film Music
Datensatz
Der Datensatz “Hollywood Film Music” (Faulkner, 2008) beschreibt die Zusammenarbeit von 40 Filmmusikkomponisten und 62 Produzenten, die mindestens fünf Filme in den Jahren 1964-1976 in Hollywood produziert haben. Eine Verbindung zwischen einem Komponisten und einem Produzenten zeigt an, dass der Komponist die Musik für den Film komponiert hat. Das Netzwerk ist gewichtet. Die Kantengewichte geben die Anzahl der Filme eines Produzenten an, für die der Komponist die Musik geschrieben hat. Ursprüngliche Daten liegen im XML-Format vor. Die Daten wurden angepasst und in das Weighted Edge List Format überführt.
Visualisierung
Auf das Netzwerk wurde der Fuzzy C Means Spectral Clustering Algorithmus angewandt. Es wurden 13 Communities erkannt.
Anhand der Visualisierung können die populärsten Komponisten aus der Sicht der Filmproduzenten festgestellt werden. Dazu gehören Goldsmith, Bernstein, Schifrin und Williams. Die Knoten, die mit Komponisten-Knoten direkt verbunden sind, stehen immer für Filmproduzenten, denn der Datensatz enthält nur Komponist-Produzent-Beziehungen und keine Komponist-Komponist- oder Produzent-Produzent-Beziehungen. Außerdem kann man sehen, dass Filmproduzenten dazu tendieren, mit denselben Komponisten zusammenzuarbeiten, so, obwohl der Datensatz 40 Komponisten, die zu selber Zeit in Hollywood tätig waren, enthält, hat Lewis nur von Goldsmith und Bernstein, Rosenberg nur von Goldsmith, Bernstein und Devol für ihre Filme Musik schreiben lassen. So kann man anhand der erkannten Communities von bestimmten Präferenzen der Filmproduzenten sprechen.
Star Wars Network
Datensatz
Der Datensatz “Star Wars Network” (Gabasova, 2016) beschreibt das soziale Netzwerk von Star Wars-Charakteren, das anhand der Filmdrehbücher erstellt wurde. Zwei Charaktere sind miteinander verbunden, wenn sie in der gleichen Szene miteinander interagieren. Die Daten enthalten Charaktere und Verbindungen aus den Episoden I bis VI. Hierbei handelt es sich um ein ungerichtetes gewichtetes Netzwerk. Die Kantengewichte geben an, in wie vielen Szenen die Charaktere miteinander interagieren. Die Knoten sind mit den Namen der entsprechenden Charaktere beschriftet. Unter dem Quelldatenlink sind einzelne Dateien für die Episoden I bis VII und eine Datei, die die Charaktere und deren Interaktionen für die Episoden I bis VI zusammenfasst. Für die Visualisierung wurden die Daten aus den Episoden I bis VI genutzt. Die Daten sind im JSON-Format verfügbar, damit das Netzwerk im WebOCD importiert werden kann, wurden die Daten in das Weighted Edge List Format überführt.
Visualisierung
Auf das Netzwerk wurde der Speaker Listener Label Propagation Algorithmus angewandt. Dabei wurden 4 Communities erkannt und es ist folgende Visualisierung entstanden:
Es fällt auf, dass die Knoten größtenteils in zwei Communities aufgeteilt sind. Diese Aufteilung entspricht ziemlich genau der Aufteilung der Charaktere in die Episoden I-III und IV-VI. So stellt die orangenfarbene Community die älteren Episoden mit Han Solo, Chewbacca, Leia und Luke als Protagonisten dar. Die hellblaue Community stellt die Episoden, die in den Jahren 1999-2005 erschienen sind, mit solchen Hauptfiguren wie Anakin/Darth Vader, Padme und Obi-Wan dar. R2-D2 gehört zum Beispiel zu den beiden Communities, denn er war in allen sechs Episoden präsent. Die Überlappung der Communities erkennt man an der Vermischung der Farben. Außerdem kann es anhand der Visualisierung festgestellt werden, welche Charaktere mehr Interaktionen miteinander hatten. Deren Knoten sind enger miteinander verbunden, so wie Leia und Han Solo oder R2-D2 und C3PO.
Zusammenfassung
Die Netzwerkanalyse und die Algorithmen zur Erkennung von überlappenden Communities können als Ergänzung zur genauen Analyse einzelner Dokumente eine Perspektive bieten, indem sie Beziehungen einer riesigen Auswahl von Dokumenten identifizieren, für deren Analyse andernfalls viel mehr Zeitaufwand entstehen würde. Mit Hilfe von WebOCD können aus den Datensätzen und Netzwerken diverse Schlussfolgerungen gezogen werden. Die Netzwerkvisualisierungen können als Illustrationen für Beziehungen und bestimmte Abhängigkeiten dienen.
In den Sprachwissenschaften kann der Wortgebrauch und die Lexik von einzelnen literarischen Werken oder vom Gesamtwerk eines Autors analysiert werden. Auf Romane und Bücherreihen angewandt kann das WebOCD dabei helfen, Aufteilungen innerhalb des Werks nach Handlungssträngen, Zeit, Territorium oder Gruppen zu erkennen, Hauptcharaktere zu bestimmen sowie Interaktionen zu visualisieren und zu analysieren. Es kann schnell die Struktur eines Romans erkannt oder der Aufbau von mehreren Werken eines Autors verglichen werden. Es können historische Prozesse analysiert werden, indem Abhängigkeiten, Interessensgebiete und Einflusszonen von Ländern, Dynastien, einzelnen Familien oder kriminellen Clans festgestellt werden. Die Netzwerkanalyse kommt bereits in den Sozialwissenschaften zum Einsatz, es kann aber auch soziale Strukturen innerhalb Gemeinschaften von Musikern, Schriftstellern und Literaturkritikern, fiktiven Figuren oder ganzen Gesellschaften untersuchen und somit für Geistewissenschaftlern von Interesse sein. Die graphische Darstellung von erkannten Communities kann als Stütze für Aussagen oder als Bestätigung der Vermutungen dienen.
Das Ergebnis hängt stark von der Qualität der genutzten Daten ab. Es können eigene Datensätze erstellt oder auf bereits vorhandene zugegriffen werden. Sollte ein Nutzer sich dafür entscheiden, fremde Datensätze zu nutzen, sollten diese vor dem Import auf Datenkonsistenz überprüft und gegebenenfalls bearbeitet werden. In vielen Fällen reicht eine kurze Anpassung mittels Funktionen im Excel, andernfalls, bei besonders umfangreichen Datensätzen, lohnt es sich ein Skript zu schreiben, das die Daten automatisch anpasst. Mit Hilfe von Skripten können auch eigene Datensätze erstellt werden. Um die Netzwerkvisualisierungen interpretieren zu können, ist das inhaltliche Verständnis von dem Thema gefragt.
Um das WebOCD in Detail kennenzulernen, können Lernmaterialien genutzt werden, die im Rahmen einer anderen Bachelorarbeit entstanden worden und unter dem folgenden Link verfügbar sind: WebOCD Teaching Materials
Links zu den Quelldaten
- Colonial/Dependency Contiguity
- David Copperfield
- Florentine Families
- George R. R. Martin’s “A Song of Ice and Fire”
- Hollywood Film Music
- Jazz Musicians
- Les Miserables
- Literature 1976
- Marvel Universe Comics
- Star Wars Network Data
- Territorial Change, 1816-2018
Referenzen
- Shahriari, M., Krott, S., & Klamma, R. (2015). WebOCD: A RESTful Web-based Overlapping Community Detection Framework. Proceedings of the 15th International Conference on Knowledge Technologies and Data-Driven Business, 51;1–4. https://www.researchgate.net/publication/283319861_WebOCD_a_RESTful_web-based_overlapping_community_detection_framework
- Correlates of War Project. Colonial Contiguity Data, 1816-2016. Version 3.1.
- Padgett, J. F., & Ansell, C. K. (1993). Robust Action and the Rise of the Medici, 1400-1434. American Journal of Sociology, 98(6), 1259–1319. http://www.jstor.org/stable/2781822
- Tir, J., Schafer, P., Diehl, P. F., & Goertz, G. (1998). Territorial Changes, 1816–1996: Procedures and Data. Conflict Management and Peace Science, 16(1), 89–97. https://doi.org/10.1177/073889429801600105
- Newman, Mark E. J. (2006). Finding community structure in networks using the eigenvectors of matrices. Phys. Rev. E, 74(3). https://doi.org/10.1103/PhysRevE.74.036104
- Knuth, D. E. (1994). The Stanford GraphBase: A Platform for Combinatorial Computing. ACM Press. https://www-cs-faculty.stanford.edu/ knuth/sgb.html
- Nooy, W. de. (1999). A literary playground: Literary criticism and balance theory. Poetics, 26(5-6), 385–404. https://doi.org/10.1016/S0304-422X(99)00009-1
- Gleiser, P. M. (2007). How to become a superhero. https://doi.org/10.48550/arXiv.0708.2410
- Gleiser, P. M., & Danon, L. (2003). COMMUNITY STRUCTURE IN JAZZ. ADVANCES IN COMPLEX SYSTEMS, 06(04), 565–573. https://doi.org/10.1142/S0219525903001067
- Faulkner, R. R. (2008). Music on demand: Composers and careers in the Hollywood film industry (3. paperback printing). Transaction.
- Gabasova, E. (2016). Star Wars social network. https://doi.org/10.5281/zenodo.1411479