Internet of Things
| Benedikt Nicoll | Cedrick Giese |
|---|---|
| RWTH Aachen University | RWTH Aachen University |
| benedikt.nicoll@rwth-aachen.de | cedrick.giese@rwth-aachen.de |
Zusammenfassung
Im Zuge des allgemeinen technischen Fortschritts werden Konzepte wie Smart Buildings oder sogar Smart Cities rasch zur Realität. Doch schon heute ist es ein großes Problem, die gigantische Datenmenge, die sich zu jedem Zeitpunkt im Internet of Things - dem zentralen Umschlagplatz für den Datenaustausch zwischen Geräten und Sensoren - befindet, zu analysieren. Eine Möglichkeit um mit dieser enormen Informationsmenge gezielt arbeiten zu können, ist die Anwendung von Algorithmen für die Entdeckung von Communities.
Im folgenden Kapitel werden wir uns mit verschiedenen Ansätzen zur Bewältigung dieser Aufgabe beschäftigen. Im Feld der Algorithmen zur Entdeckung von nicht-überlappenden Communities werden wir uns drei unterschiedlichen Ansätzen widmen, einen der auf globalen Attributen und einen der auf lokalen Attributen basiert sowie einen der beide Ansätze kombiniert.
Zusätzlich zu den Erläuterungen der Funktionsweisen werden wir insbesondere auf mögliche Anwendungsszenarien im Bereich des Internet of Things eingehen. Dabei werden wir feststellen, dass die klar abgegrenzten Communities eine Struktur in die Unordnung des Internet of Things bringen und somit bei der Datenverarbeitung einen klaren Vorteil einbringen.
Inhaltsverzeichnis
I. Einleitung
Das sogenannte Internet of Things (im Folgenden “IoT”) dient zur Integration der physischen Welt in die virtuelle Welt des Internets. Dies geschieht durch den ständigen Austausch von Daten zwischen den beteiligten Komponenten. Zu besagten Komponenten zählt ein breiter Bereich von Geräten, so auch insbesondere die Sensoren von Haushaltsgeräten, Kraftfahrzeugen, Handys oder Medizinischer Ausrüstung. Eine mögliche Anwendung ist zum Beispiel die Kommunikation zwischen Fahrzeugen, was insbesondere im Bereich des autonomen Fahrens eine zentrale Rolle spielt. Schon heute gibt es einen Ausblick auf gesamte Großstädte, sogenannte Smart-Cities, die vollkommen vernetzt sind. So zum Beispiel das große Testgelände SmartSantander in Spanien, welches ungefähr 3000 IoT Geräte und weitere 200 Geräte, welche als Brücke zwischen den IoT Geräten dienen, verwaltet. Ziel ist der Erhalt von Daten, wie sie in einer großflächigen Smart-City anfallen würden. Dies umfasst insbesondere eine völlig vernetzte Infrastruktur, welche den generellen Verkehrsfluss, Fahrräder, Taxis, generelle Umgebungsdaten (z.B. Temperatur) und vieles Weiteres berücksichtigt. Eine mögliche Anwendung dieser Vernetzung, ist zum Beispiel die Erfassung von Fußgängern in der Dunkelheit, um die Beleuchtung spezifisch an die Situation anzupassen. So können nicht benötigte Straßenlampen abgeschaltet werden, ohne dass für einen Fußgänger Nachteile entstehen.
Mit der rasch wachsenden Komplexität der Netzwerke im Internet of Things, wächst auch die Menge an Daten, die innerhalb dieser ausgetauscht und bearbeitet werden. Die von Sensoren generierten Daten wachsen in einer beispiellosen Größenordnung, teilweise sogar um Petabytes(\(10^{15}\) Bytes). Durch dieses Wachstum wird es zunehmend schwieriger, diese Daten effizient und präzise zu analysieren. Eine Lösung, die eine solche Analyse dennoch möglich machen kann ist der Prozess des Data Clustering. Data Clustering beschreibt die Klassifizierung oder Ordnung von Daten in Gruppen, sogenannte Cluster (Jain & Murty, 01-SEP-1999). Um das Problem des Data Clusterings im IoT zu lösen, bietet sich unter anderem Community-Detection an. Dies ermöglicht es das gesamte Netzwerk auf viele, kleinere, stark vernetzte Teilnetzwerke (Communities) herunterzubrechen. Jedoch erfordert der Einsatz in einem so stark skalierendem Netzwerk wie dem IoT, grundlegende Überarbeitungen dieser Techniken, um ihre Zukunftsfähigkeit zu gewährleisten.
Viele der aktuell bekannten Community-Detection-Algorithmen sind dementsprechend nicht geeignet für einen Einsatz auf diesen Datenmassen. Insbesondere Overlapping-Community-Detection-Algorithmen (im Folgenden “OCD”) sind eher ungeeignet für diese Aufgabe, da diese selten effizient mit solch großen Netzwerken arbeiten können. Doch auch die Non-Overlapping-Community-Detection-Algorithmen, welche meist zeiteffizienter sind, schwächeln dennoch beim Einsatz im IoT. Aus diesem Grund wird vermehrt nach Anpassungen bestehender Algorithmen oder sogar der Entwicklung völlig neuer Algorithmen geforscht, um eine geeignete Genauigkeit und Zeiteffizienz beim Einsatz in einem IoT Netzwerk zu gewährleisten. Im Folgenden werden drei dieser Ansätze vorgestellt, um einen Überblick über dieses zerstrittene Themenfeld zu gewähren. Dabei werden wir insbesondere die grundverschiedenen Ansätze der Algorithmen sowie ihre Nützlichkeit im IoT beschreiben. Abschließend werden wir einen kurzen Einblick auf Einsatzmöglichkeiten bieten, die sich durch die Anwendung der Community Detection eröffnen.
II. Verwandte Arbeiten
Dieses Kapitel bezieht sich vor allem auf die Erkenntnisse der folgenden drei Paper, welche unterschiedliche Herangehensweisen an das Problem der Community Detection im Bereich des IoT untersuchen: “A Novel Community Detection Algorithm Based on Pairing, Splitting and Aggregating in Internet of Things”(Li et al., 2020),”Big Data Clustering via Community Detection and Hyperbolic Network Embedding in IoT Applications”(Karyotis et al., 2018) und “DLCD-CCE: A Local Community Detection Algorithm for Complex IoT Networks”(Xu et al., 2020). Außerdem wurde sich auf klassiche nOCD-Algorithmen wie Girvan-Newman(Newman, Mark E. J. & Girvan, 2004) und Louvain(Blondel et al., 2008) bezogen. Der Zweck dieses Kapitels ist nicht eine vollständige Wiedergabe der Inhalte dieser Paper, sondern viel eher einen Überblick über diese Thematik auf deutscher Sprache zu bieten.
III. Methodik
Im Gegensatz zu den Inhalten vorherigen Auflagen werden wir in diesem Kapitel Non-Overlapping-Community-Detection-Algorithmen (im Folgenden “nOCD-Algorithmen”) vorstellen. Diese unterscheiden sich im Wesentlichen dadurch von OCDs, dass jeder Knoten zu jedem Zeitpunkt immer nur exakt einer Community zugeordnet ist. Dadurch werden die Rechnungen offensichtlich weniger komplex, was jedoch auch zu festen Community-Grenzen führt. Da es in vielen Anwendungsgebieten eher interessant ist, die Übergänge und Schnittmengen von Communities zu betrachten, sind nOCD-Algorithmen für diese ungeeignet. Doch das Themenfeld des IoT erfordert eher eine schnelle Berechnung als fließende Übergänge zwischen den Communities. Deswegen konzentriert sich die Forschung in diesem Einsatzbereich auf nOCD-Algorithmen.
Non-Overlapping-Community-Detection am Beispiel Louvain
Ein bekannter nOCD-Algorithmus, der sich insbesondere durch seine Zeiteffizienz auszeichnet ist der Louvain Alogrithmus (Blondel et al., 2008). Dieser basiert auf der erhöhten Dichte von Kanten zwischen Mitgliedern einer Community im Vergleich zu der Dichte von Kanten zwischen Communities. Weiterhin basiert Louvain auf dem Konzept der Modularität eines Graphen. Die Modularität eines Graphen ist ein skalarer Wert zwischen \(-1\) und \(1\), der die Dichte der Verbindungen innerhalb der Communities im Gegensatz zu der Dichte außerhalb der Communities vergleicht. Für gewichtete Graphen ist die Modularität wie folgt definiert:
\(Q = \frac{1}{2m}∑_{i, j} [A_{ij} - (\frac{k_ik_j}{2m})] \delta(c_i, c_j)\),
wobei \(A_{i,j}\) das Gewicht der Kante zwischen \(i\) und \(j\) ist, \(k_i = ∑_j A_{ij}\) ist die Summe aller Kantengewichte eines Knoten \(i\), \(c_i\) ist die Community, in der sich der Knoten \(i\) befindet, die \(\delta\)-Funktion \(\delta(c_i, c_j)\) ist \(1\) wenn \(u = v\) und sonst \(0\) und \(m = \frac{1}{2}∑_{i, j} A_{i, j}\). Die Modularität \(Q\) ist ein beliebtes Maß für die Qualität der erhaltenen Communities und wird unter anderem benutzt um eine optimale Partition zu ermitteln (nähere Informationen unter Modularity Optimization).
Louvain betrachtet für jeden Knoten, ob die Modularität des Graphen erhöht werden kann, indem man diesen Knoten in die selbe Community wie sein Nachbar einfügt. Dies wird für alle Nachbarn des Knoten ausgeführt. Anschließend wird das Maximum ermittelt um die passendste Community zu finden. Sollte die Modularität nicht erhöht werden können, so bleibt der Knoten in seiner aktuellen Community.
Der Algorithmus wird in zwei Phasen ausgeführt: In der ersten Phase wird die bereits beschriebene Modularitätsoptimierung ausgeführt. In der zweiten Phase wird aus den gefundenen Communities ein neuer Graph errichtet. Die gefundenen Communities werden zu den neuen Knoten des Graphen. Die Summe aller Kantengewichte zwischen zwei Communities bestimmt das Gewicht der Verbindungskante zwischen den Communitiy-Knoten. Selbiges gilt auch für Kanten innerhalb einer Community, welche als Selbstschleife in die den Community-Knoten führen. Anfänglich ist jeder Knoten in seiner eigenen Community, die beiden Phasen werden dann iterativ so oft ausgeführt, bis es keinen Fortschritt mehr bei der Modularitätsoptimierung gibt.
Dieses Verhalten verdeutlicht sehr gut die Unterschiede zwischen OCD und nOCD. Im Gegensatz zu den Überlappungen, welche in OCD-Algorithmen gefunden werden, gehört in einem nOCD Algorithmus ein jeder Knoten nur zu genau einer Community. Dies erschafft klare Grenzen zwischen den Communities. Während ein solches Vorgehen viel zu plump wäre, um zum Beispiel auf einem soziales Netzwerk einzusetzen, eignet es sich jedoch sehr gut, um auf großen Datenmengen eingesetzt zu werden. Dies liegt dran, dass der Rechenaufwand relativ gering gehalten ist. So stößt laut Aussage der Autoren der Louvain-Algorithmus mit seiner linearen Laufzeit im Gegensatz zu allen anderen Community-Detection-Algorithmen bezüglich der Netzwerkgröße eher beim begrenzten Speicher als bei der begrenzten Rechenzeit an seine Grenzen (Blondel et al., 2008). Auch unsere eigenen Test bestätigen die Effizienz des Algorithmus(Tests wurden ausgeführt auf einem AMD Ryzen 7 1700X Prozessor). So benötigte der Algorithmus für ein Netzwerk mit mehr als 3 Millionen Knoten und mehr als 117 Millionen Kanten weniger als 19 Minuten (1114 Sekunden).
Die erhöhte Zeit- und Platzkomplexität, die nOCD-Algorithmen bieten, ist der Hauptgrund, warum in einer so komplexen Umgebung wie dem IoT diese Algorithmen den OCD-Algorithmen vorgezogen werden. Generell lassen sich nOCD-Algorithmen in 3 Klassen unterteilen, welche sich auf verschiedene Attribute beziehen: lokal, global und hybrid.
Die auf globalen Attributen basierende hode nutzt meist den gesamten Graphen als Parameter bis alle Communities entdeckt wurden. Dabei werden immer die Beziehungen im gesamten Graph betrachtet. So wird zum Beispiel im Girvan-Newman-Algorithmus der gesamte Graph nach Brücken zwischen Communities untersucht, um diese zu löschen und somit die Communities zu isolieren. Die auf lokalen Attributen basierende Methode im Gegenzug kann die Berechnungskomplexität deutlich senken, dies geschieht jedoch auf Kosten der Qualität der gefundenen Communities. Diese weisen oft starke Schwankungen zwischen ihrer Größe auf. Ein Beispiel dafür wären Algorithmen, welche auf dem Konzept von Random Walks basieren. Diese bauen darauf auf, dass ein “Wanderer”, der zufällige Kanten entlang läuft, eher in einer Community bleibt als sie zu verlassen. Dies ist auf die hohe Dichte der Kanten innerhalb einer Community zurückzuführen (nähere Informationen unter Random Walks). Einige Algorithmen nutzen auch weitere lokale Knotenattribute, wie zum Beispiel die Ähnlichkeit von Knoten. Zuletzt gibt es noch die hybride Methode, welche versucht beide Ansätze zu vereinen. Dies soll das Beste aus beiden Ansätzen vereinen, teilt jedoch gleichermaßen auch häufig die selben Schwächen.
Welche dieser drei Varianten am ehesten für das Feld des IoT geeignet ist, ist stark debattiert. Um die Vielfältigkeit dieses Themenfeldes besser zum Ausdruck zu bringen, werden wir im Folgenden aus jeder Kategorie jeweils einen Algorithmus vorstellen, der spezifisch auf den Einsatz im IoT ausgerichtet ist. Den Anfang macht der Hyperbolic-Girvan-Newman Algorithmus, welcher den klassischen Girvan-Newman Algorithmus so abändert, dass er ohne großen Genauigkeitsverlust die Zeiteffizienz deutlich steigert. Danach betrachten wir den DLCD-CCE-Algorithmus welcher auf lokaler Ebene arbeitet und über das Erweitern von Community-Zentren funktioniert. Zuletzt betrachten wir noch den Pairing-Splitting-and-Aggregating-Algorithmus, welcher einen hybriden Ansatz darstellt.
Hyperbolic Girvan-Newman
Girvan-Newman
Einer der intuitivsten Ansätze um Communities zu entdecken ist es wohl die verbindenden Brücken zu kappen und die Communities somit zu isolieren. Ein solcher Ansatz wurde schon 2003 von Girvan und Newman untersucht (Newman, Mark E. J. & Girvan, 2004). Im Girvan-Newman-Algorithmus(im Folgenden “GN”) werden in einem ersten Schritt die Anzahl der Zielcommunities definiert. Anschließend werden alle Kanten des Graphen bezüglich ihrer Edge-Betweenness-Centrality (im Folgenden “EBC”) geordnet. Dieser Wert beschreibt für jede Kante des Graphen die Anzahl der kürzesten Pfade zwischen jeglichen Knotenpaaren des Graphen, die diese Kante überqueren. Die Kante mit der höchsten EBC, welche also am ehesten als Brücke zwischen Communities dient, wird entfernt. Dieser Vorgang wird solange wiederholt bis der Graph in unverbundene Teilgraphen zerfällt. Insbesondere sei zu beachten, dass nach dem Entfernen jeder Kante der EBC-Wert aller Kanten neu berechnet werden muss. Das selbe Vorgehen wird dann auf jedem größten Teilgraph des Gesamtgraphen wiederholt bis die gewünschte Anzahl Communities erreicht ist. Dieser Algorithmus ist jedoch ungeeignet, um ihn auf einem großen Datenset einzusetzen, da es aufgrund der wiederholten Berechnung des EBCs für jede Kante zu einer sehr hohen Laufzeit kommt.
Hyperbolische Netzwerk Einbettung
Um dieses Problem zu beheben und den GN-Algorithmus an das Internet of Things anzupassen, wird das Konzept von Hyperbolic-Girvan-Newman(im Folgenden “HGN”) vorschlagen(Karyotis et al., 2018). Dies geschieht über das Einbetten des Graphen in den hyperbolischen Raum. Hyperbolische Netzwerke detailliert zu erklären, würde diese Arbeit deutlich verlängern und verkomplizieren, weswegen wir im Folgenden nicht weiter auf die Eigenschaften des hyperbolischen Raumes eingehen, es sei denn sie sind relevant für die Funktionsweise von HGN. Vom Konzept her kann man sich dies wie folgt vorstellen: Ein großer und komplizierter Graph wird in einen Raum mit niedrigerer Dimension eingebettet, indem jedem Knoten eine bestimmte Koordinate in diesem Raum zugewiesen wird. Dies ermöglicht eine effizientere Berechnung der nächsten zu entfernenden Kanten, da das Problem ohne großen Genauigkeitsverlust auf eine leichter zu berechnende Form reduziert werden kann. Eine weitere wichtige Veränderung des HGN liegt darin, dass Kanten nicht einzeln sondern in Gruppen (sogenannten “Batches”) entfernt werden. Weiterhin wird die EBC angepasst zu Hyperbolic-Edge-Betweenness-Centrality (im Folgenden “HEBC”). Diese nutzt zur Berechnung die Koordinaten der eingebetteten Knoten im hyperbolischen Raum. Die Einbettung des Graphen funktioniert grob vereinfacht wie folgt: Zuerst werden einige Landmarken-Knoten ausgewählt, deren genaue Position im hyperbolischen Raum genauer berechnet wird als die der anderen Knoten. Für alle anderen Knoten werden die hyperbolischen Koordinaten in Abhängigkeit von ihrer Distanz zu den Landmarken berechnet, sodass die hyperbolische Distanz zu jeder Landmarke so nah wie möglich an die Distanz im Ursprungsgraphen herankommt. Die Berechnung des HEBC erfolgt schließlich dadurch, dass ein Zielknoten gewählt wird und jeder mögliche Anfangsknoten des Pfades bezüglich seiner hyperbolischen Distanz zum Zielknoten geordnet wird. Dies ermöglicht das Abarbeiten in korrekter Reihenfolge in den nächsten Schritten.
Unterschiede zwischen HGN und GN
Der nächste Unterschied zu GN besteht in der Art und Weise, in der die kürzesten Pfade bestimmt werden. Während in GN tatsächlich die kürzesten Pfade bestimmt werden, werden in HGN lediglich greedy paths bestimmt. Diese bieten den Vorteil, dass diese leichter zu finden sind, da immer die Kante gewählt wird, welche so nah wie möglich an den gewünschten Zielknoten heranführt. Die Anzahl der greedy paths ist dabei nicht immer gleich der Anzahl der tatsächlichen kürzesten Pfade, was zu einem abweichendem Wert zwischen HEBC und EBC führt. Dennoch ist die Ordnung der Kanten nach HEBC sehr nah an der Ordnung nach EBC. Zuletzt werden für jeden Knoten die Abhängigkeiten bezüglich der anderen Knoten berechnet. Dies ermöglicht eine effiziente Abarbeitung aller Kanten, da der selbe greedy path nicht für jeden Knoten, den er durchquert erneut berechnet werden muss. Anschließend wählt der Algorithmus einen neuen Startknoten und wiederholt den Vorgang solange bis alle Knoten abgearbeitet wurden und somit alle HEBC-Werte berechnet wurden.
Hyperbolic-Girvan-Newman ähnelt nun im Ablauf stark dem originalen GN-Algorithmus. Wie auch bei diesem werden so lange Kanten entfernt, bis die gewünschte Anzahl Communities erreicht ist. Dabei wird der größte Teilgraph in den hyperbolischen Raum eingebettet, um dann die HEBC Werte für jede Kante zu berechnen. Wie in GN werden nun die Kanten mit dem höchsten HEBC-Wert entfernt bis der Graph in weitere Teilgraphen zerfällt. Im Unterschied zu GN werden die Kanten mit den höchsten HEBC-Werten zu einem Batch zusammengefasst, wodurch kritische Kanten auf Kosten der Genauigkeit schneller entfernt werden können. Sollte der Batch vollständig geleert werden, wird der HEBC-Wert für jede Kante neu berechnet, um so einen neuen Batch zu schaffen. Dies wird so lange wiederholt bis die gewünschte Anzahl Communities erreicht wird. Der generelle Programmablauf ist im folgenden Bild schematisch dargestellt:
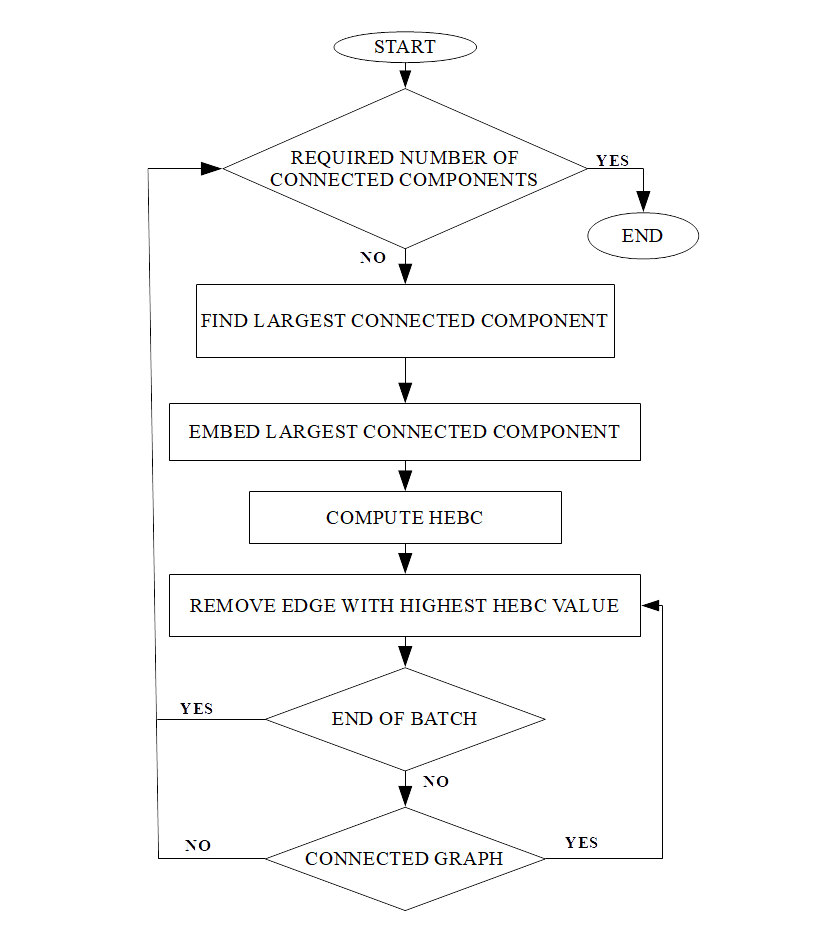
Abb. 1: Ablauf von HGN (Karyotis et al., 2018)
Die vorgenommen Veränderungen wirken zwar in kleinen Netzwerken eher nachteilig auf die Laufzeit, je größer das Netzwerk jedoch wird, desto deutlicher wird die Verbesserung, welche HEBC bietet. Deutlich schneller wird HGN schon ab einer Graphengröße von 400 Knoten. So terminiert HGN auf Netzwerken mit 800 Knoten zum Beispiel bis zu acht Mal schneller als GN. Die Tests der Autoren haben gezeigt, dass auch die Modularität sich in einem ähnlichen Rahmen bewegt, wie der herkömmliche GN und sie in einigen Fällen sogar übersteigt (Karyotis et al., 2018). Großer Nachteil von GN und HGN bleibt jedoch, dass die Anzahl der gewünschten Communities als Eingabe gegeben werden muss, da sonst der Graph bis in Einzelknoten zerlegt werden würde. Dennoch erlaubt die Einbettung in den hyperbolischen Raum eine viel bessere Fähigkeit mit den stark skalierenden Daten im IoT umzugehen, was sogar auf Daten des Testgeländes SmartSantander bestätigt werden konnte.
Distributed Local Community Detection algorithm based on specific properties of Community Centre Expansions
Als Beispiel für einen Algorithmus welcher den lokalen Ansatz verfolgt, stellen wir “Distributed Local Community Detection algorithm based on specific properties of Community Centre Expansions” (im Folgenden als “DLCD-CCE”) vor. Dieser wurde von Xiaolong Xu (Xu et al., 2020) entwickelt und er verwendet das Apache Spark Framework mit GraphX. Spark wurde gewählt, da es zum einen effizienter und schneller ist als Apache Hadoop und zum anderen besseren Community Support als Apache Flink welches zusätzlich auf großen Datensets auch langsamer ist.
Drei für DLCD-CCE wichtige lokale Kenngrößen sind “Relationship Density”, “Community Centrality” und “Community Attractiveness”.
Relationship Density bezieht sich auf die Nähe eines Knotens zu seinen Nachbarknoten. Ist die Relatonship Density eines Knotens höher, bildet dieser über seine Kanten mehr Dreiecke mit seinen Nachbarn. Sie wird berechnet aus dem Grad des Knotens und seinen Kantengewichten.
Die zweite Eigenschaft ist Community Centrality, welche die Wichtigkeit eines Knotens innerhalb seiner Community beschreibt, wobei wichtige Knoten höheren Einfluss haben.
Zuletzt gibt es noch die Community Attractiveness. Diese bezeichnet die Attraktivität einer Community für externe Knoten und ist wichtig in der Community-Center Expansion.
Wie bereits erwähnt, sind diese Attribute lokal, das heißt sie können unabhängig vom Gesamtgraph bestimmt werden.
DLCD-CCE unterteilt sich in drei Phasen:
- Berechnung der Zentralität
- Identifikation der Community-Zentren
- Erweiterung der Community Zentren
Im ersten Schritt wird für jeden Knoten die jeweilige Community Zentralität ermittelt. Anschließend werden Community-Zentren mithilfe von Random Walks ausfindig gemacht (nähere Informationen unter Random Walks). Wichtig ist hierbei, dass die Anzahl der Schritte durch eine konstante beschränkt ist, weshalb DLCD-CCE im Gegensatz zu manchen anderen Anwendungen von Random Walk nicht von den Seeds der einzelnen Walks abhängt. Im dritten und letzten Schritt werden die zuvor gefunden Community-Zentren iterativ erweitert. Hier wählt der Algorithmus in jeder Iteration eine Gruppe von Knoten neben einer Community und überprüft die Community Attractiveness zu den einzelnen Knoten. Ist diese höher als ein bestimmter Schwellwert, wird der Knoten hinzugefügt, andernfalls nicht. Anschließend wird der Community Cohesion Coefficient der Community bestimmt, wofür die Summen der ein- und ausgehenden Kanten verwendet werden. Sobald dieser nicht mehr steigt, das heißt sobald die Zusammengehörigkeit der Community nicht mehr steigt, hört der Algorithmus auf, zu iterieren.
Dadurch, dass alle Operationen auf lokalen Graphattributen stattfinden, zeigt sich ein weiterer Vorteil von DLCD-CCE: im Falle eines großen, verteilten Rechensystems lässt er sich leicht parallelisieren, sodass kein Rechner Operationen auf dem gesamten Graph ausführen muss. Hier wird der Graph in eine Menge von Tripeln zerlegt, die aus einem Anfangsknoten, einem Zielknoten und dem Kantengewicht zwischen den beiden bestehen. Somit entspricht jedes Tripel einer Kante des Graphen. Um den Algorithmus nun zu parallelisieren, wird der Graph in einem verteilten System gespeichert, sodass einzelne Operationen auf lokalen Tripeln ausgeführt werden können. Hierfür wird die Berechnung so aufgeteilt, dass sie nach dem Teilen-und-Herrschen-Prinzip als Summe vieler Operationen auf einzelnen Tripeln realisiert werden kann.
Insgesamt ist DLCD-CCE aufgrund der du Parallelisierung, die durch die Verwendung von lokalen Attributen ermöglicht wird, äußerst skalierbar. Somit eignet er sich auch für große Netzwerke, wie sie im Internet of Things vorhanden sind. Außerdem ist er, da er auf Spark GraphX basiert einfach auf existierenden Netzwerken implementierbar.
Pairing, Splitting, Aggregating
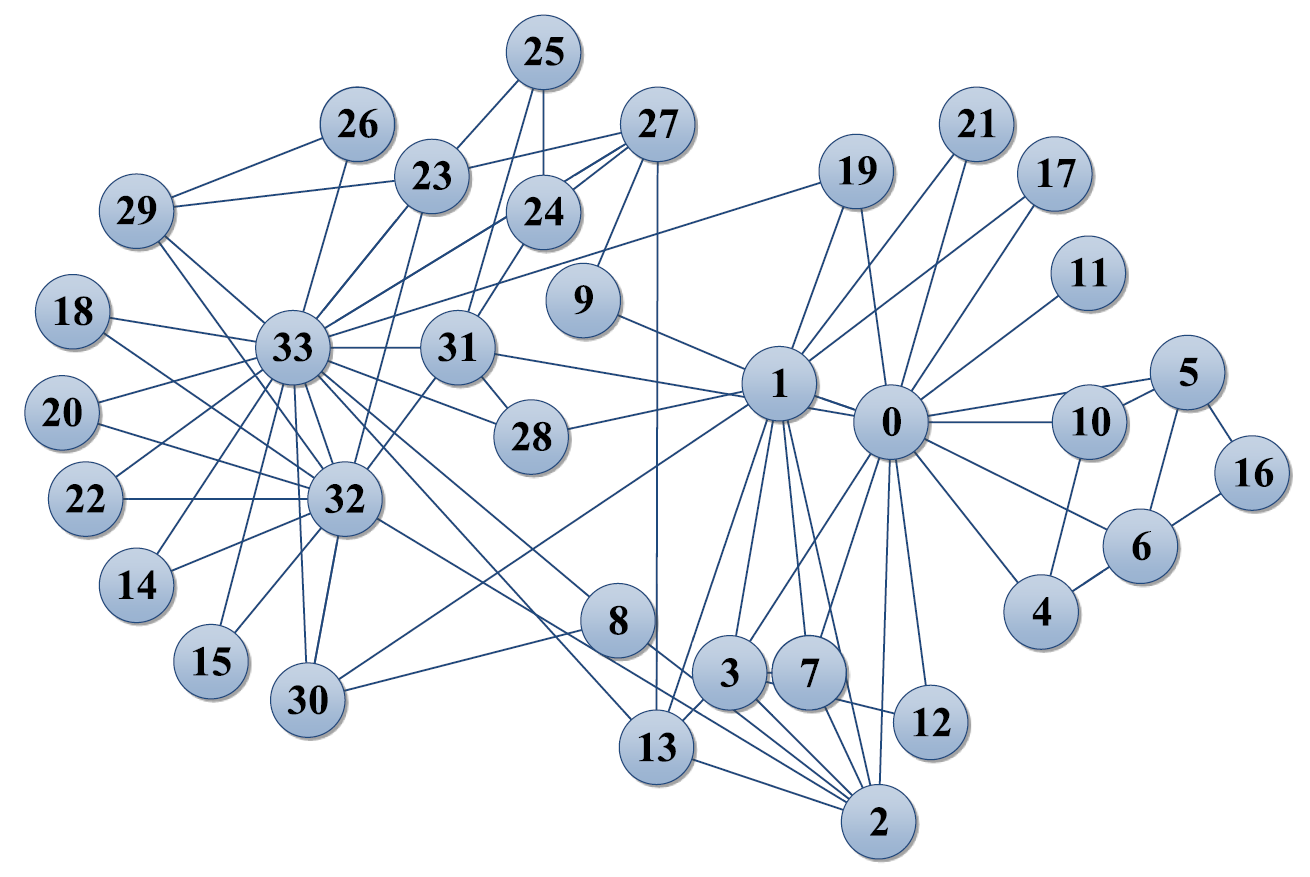
Abb. 2.1: Netzwerkgraph von “Zachary’s karate club” (Li et al., 2020)
Der im Paper “A Novel Community Detection Algorithm Based on Paring, Splitting and Aggregating in Internet of Things” von Yizhe Le (Li et al., 2020) vorgestellte Algorithmus (im Folgenden “PSA”) verfolgt einen hybriden Ansatz zur non-Overlapping-Community-Detection. Dabei unterteilt sich PSA in drei Phasen: Pairing, Splitting, Aggregating. Wobei zuerst die Knoten so in Paare geordnet werden, dass jeder Knoten eine Verbindung zu allen Knoten haben, die die größte Ähnlichkeit mit ihm ausweisen. Dies geschieht um im späteren Verlauf bei teuren Berechnungen repetitive Rechenarbeit zu sparen. Anschließend werden diese Mengen zu einem neuen Graphen zusammengesetzt. In diesem werden nun die Mengen von ähnlichen Knoten so vereint, dass sie Communities bilden. Im Folgenden ist der Ablauf des Algorithmus dargestellt an dem bekannten Datenset von “Zachary’s karate club” (Abb. 2.1). Dieses stellt die Kommunikation zwischen den Mitglieder eines Karateclubs dar, welcher in 2 Hälften gespalten ist.
Pairing

Pseudocode der Pairing-Phase (Li et al., 2020)
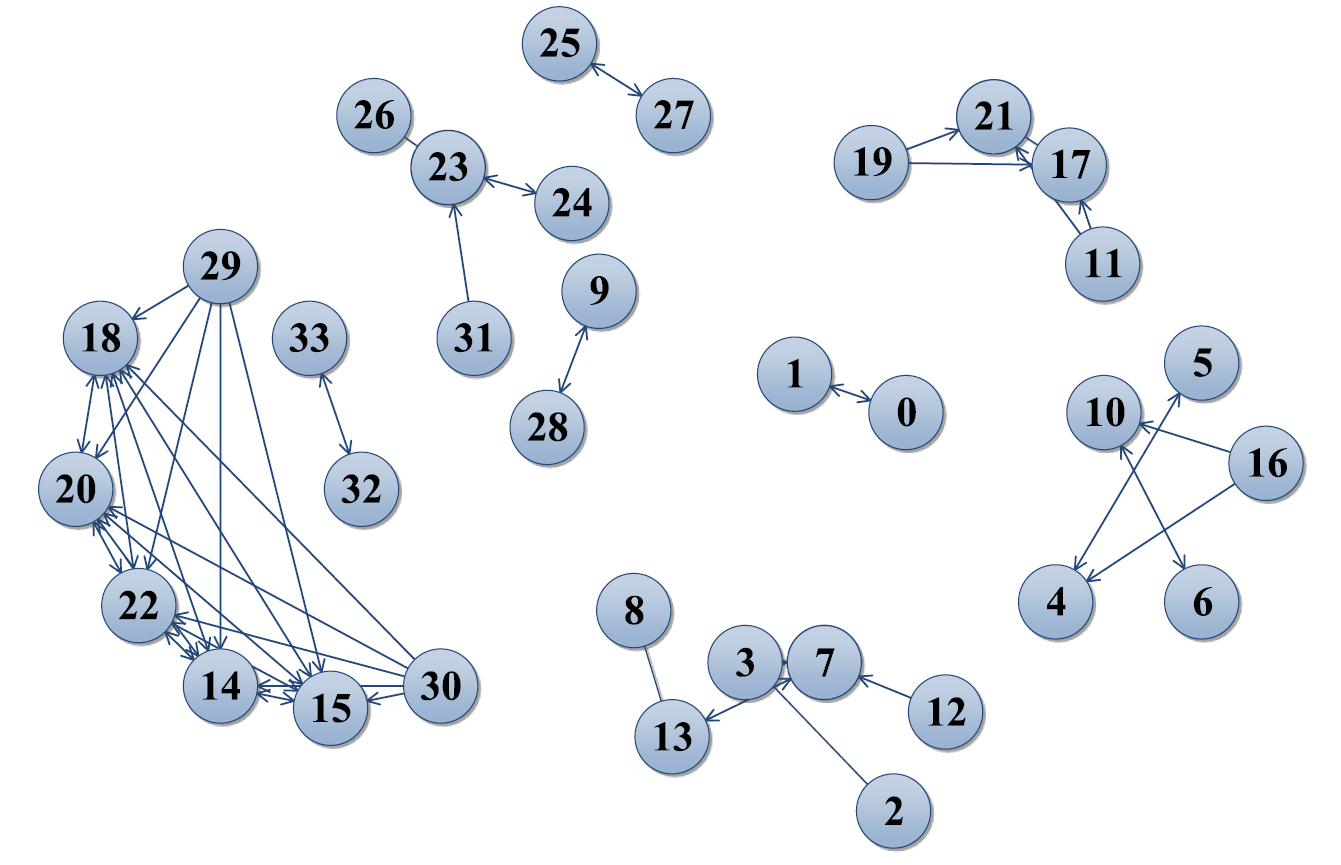
Abb. 2.2: Ergebnis der Pairing-Phase (Li et al., 2020)
In der ersten Phase “Pairing”, wird zuerst die Similarity Matrix \(SM\) angelegt und mit \(SM_{i,j}=0\) initialisiert, wobei \(i\) und \(j\) Knoten aus dem betrachteten Graphen sind. \(SM_{i,j}\) beschreibt den Similarity Index, also die Ähnlichkeit der Knoten \(i\) und \(j\); es werden also alle Knoten mit dem Similarity Index 0 initialisiert. Nun durchläuft der Algorithmus jeden einzelnen Knoten des Graphen und überprüft paarweise den Similarity Index seiner Nachbarn untereinander. Ist dieser noch auf dem Initialwert 0, wird er entsprechend einer Funktion \(\phi\) aktualisiert. Dabei berechnet \(\phi (i,j)\) die Ähnlichkeit zwischen den Nachbarknoten \(i\) und \(j\) eines Knotens \(v\). Das Ergebnis wird in \(SM_{i,j}\) gespeichert, damit schlussendlich aus der Matrix \(SM\) entnommen werden kann, welche Knoten \(j\) dem Knoten \(i\) am ähnlichsten sind. Dabei sei insbesondere zu beachten, dass mehrere Knoten die maximale Ähnlichkeit erreichen können. Nach dieser Phase ist das gesamte Netzwerk also in Paare von ähnlichen Knoten zerlegt (Abb. 2.2).
Splitting
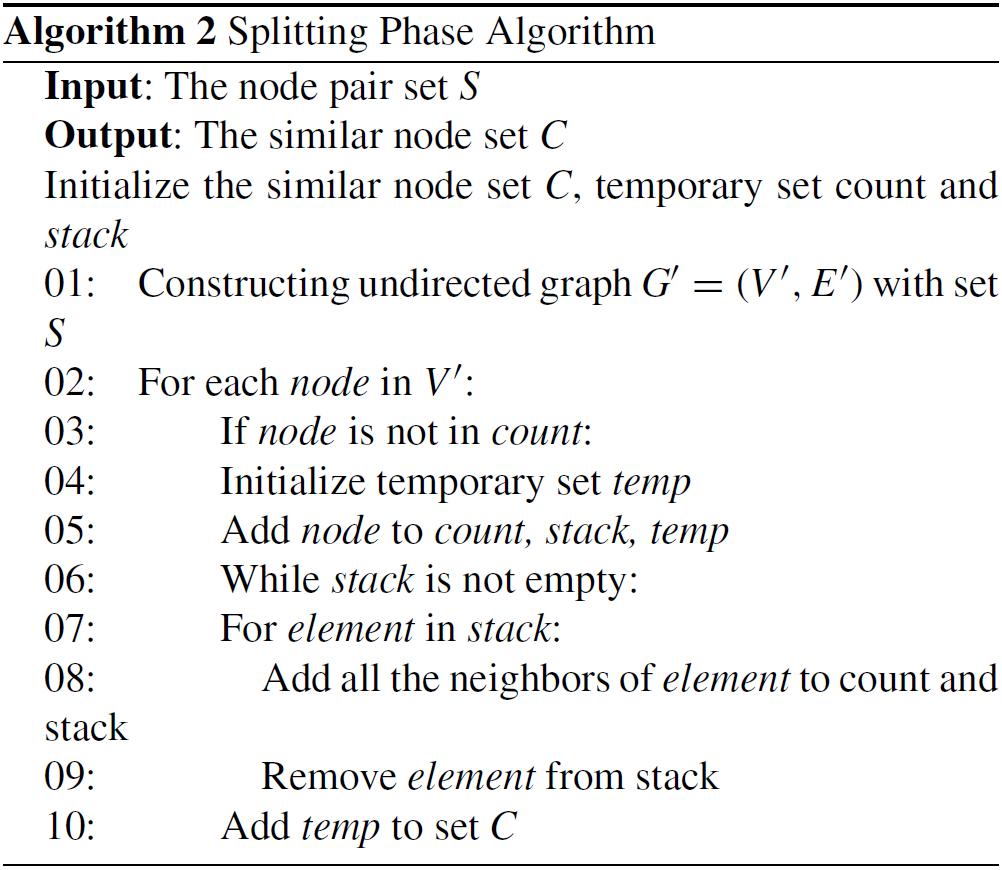
Pseudocode der Splitting-Phase (Li et al., 2020)
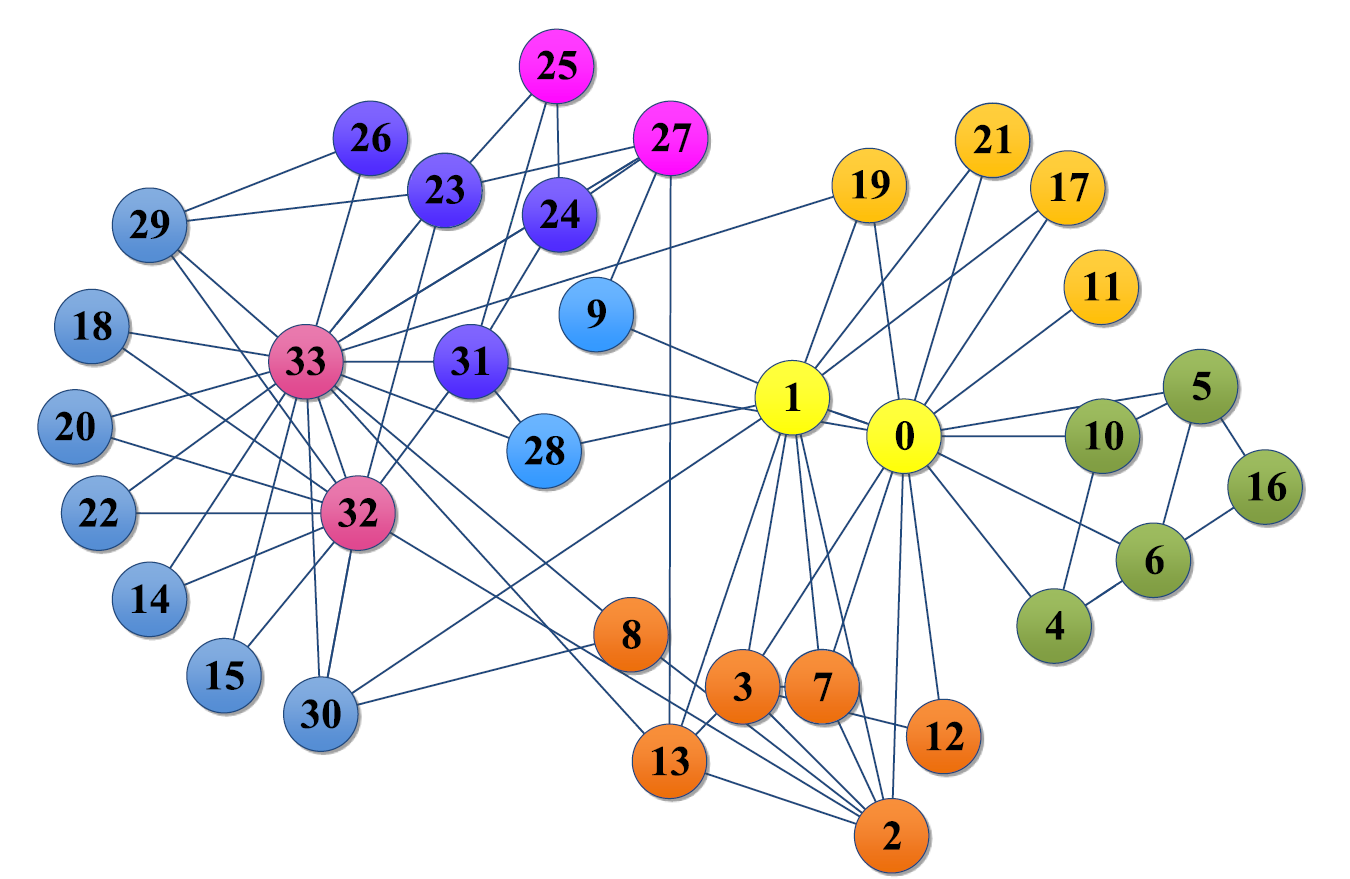
Abb. 2.3: Ergebnis der Splitting-Phase (Li et al., 2020)
In der zweiten Phase “Splitting” nutzen wir das Vorwissen aus der ersten Phase über ähnliche Knotenpaare, um den Graph in Gruppen von ähnlichen Knoten zu unterteilen. Dies geschieht durch die Auswahl eines bisher unmarkierten Knotens, der zur temporären Menge \(temp\) und dem \(stack\) hinzugefügt wird. Anschließend wird für jeden Knoten im \(stack\) der Knoten markiert, aus dem \(stack\) gelöscht und all seine Nachbarn (also alle ähnliche Knoten) zum Stack hinzugefügt. Sollten alle Knoten abgearbeitet sein, so wird die Menge der Knoten in \(temp\) (also die Menge alle Knoten mit höchster Ähnlichkeit zueinander) zur Menge der ähnlichen Knotenmengen \(C\) hinzugefügt. Dieser Prozess wird so lange wiederholt, bis alle Knoten des Graphen markiert wurden und somit alle ähnlichen Knotenpaare einer Menge von ähnlichen Knoten angehören (Abb. 2.3).
Aggregating

Pseudocode der Aggregating-Phase (Li et al., 2020)
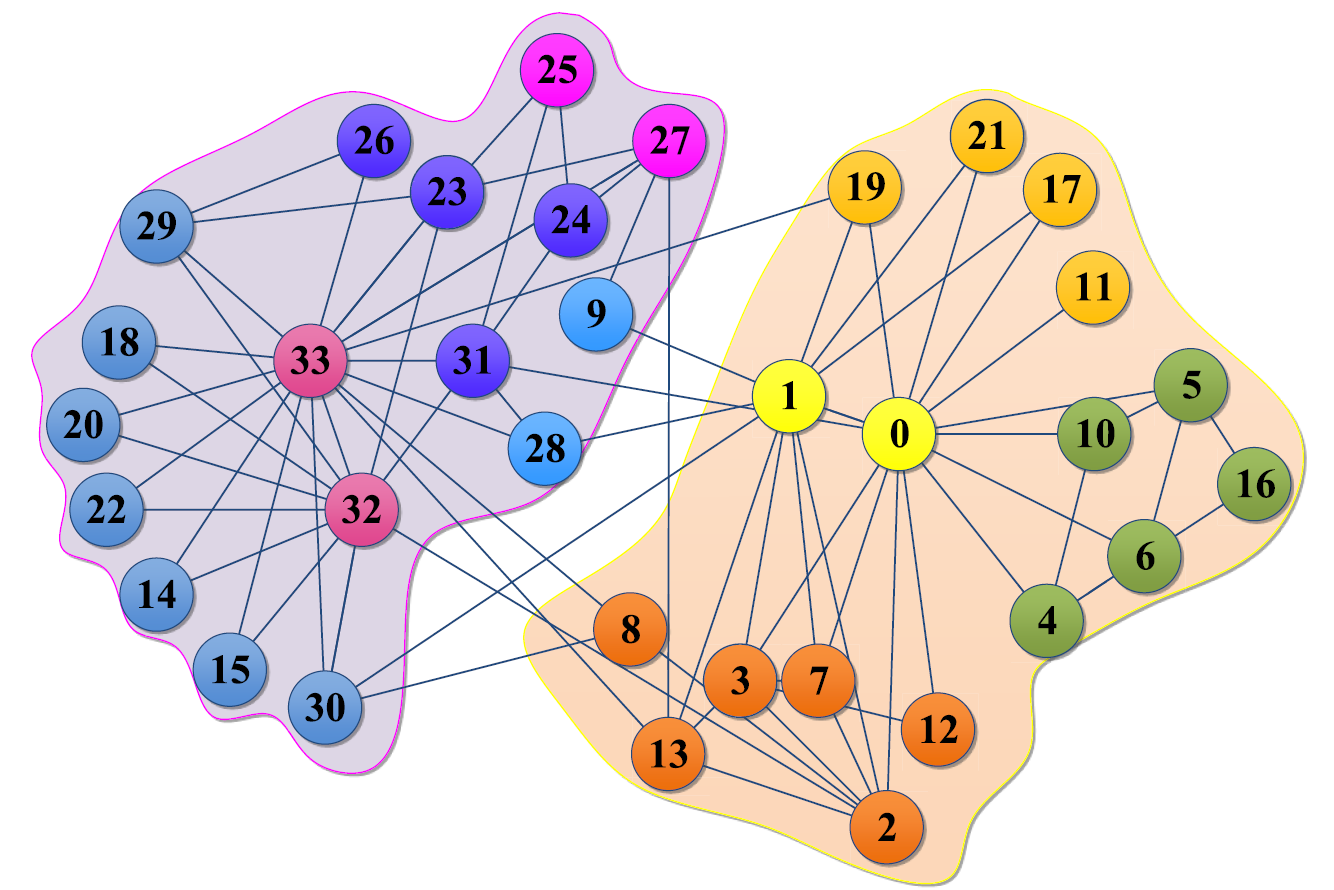
Abb. 2.4: Ergebnis der Aggregating-Phase (Li et al., 2020)
In der dritten und letzten Phase werden nun noch die Beziehungen zwischen den verschiedenen ähnlichen Knotenmengen untersucht, um sie zu Communitites zusammenzufügen. Dabei wird insbesondere darauf geachtet, dass die gefundenen Communities nicht zu unbalanciert sind, wie es sonst häufig in lokalen und hybriden Methoden der Fall ist. Dies geschieht dadurch, dass zuerst die benachbarten Knotenmengen ausgemacht werden. Weiterhin wird für jede benachbarte Knotenmenge überprüft, ob die Zusammenfassung der Mengen nicht zu einer zu großen Ansammlung von Kanten und Knoten führt. Anschließend wird die Nachbarmenge berechnet, welche beim Zusammenschluss die Balance der Knotenmengengröße am wenigsten verschlechtert. All dies geschieht durch den so gennanten Grasshoper Optimization Algorithmus. Diesen kann man sich vorstellen, wie eine Menge von Grashüpfern, die genau dann auf benachbarte Knotensets hüpfen, wenn diese Bedingungen gegeben sind. Bewegen sich die Grashüpfer von einer Menge \(i\) zu einer Menge \(j\), so werden diese zu einer neuen Knotenmenge zusammengefügt. Dies wird so lange wiederholt, bis die Grashüpfer sich nicht mehr bewegen können, also der Graph nicht weiter verändert werden kann, ohne die Balance der Communities oder die Modularität zu senken.
V. Zusammenfassung und Ausblick
In diesem Kapitel wurde die Nutzung von Community Detection im Internet of Things und insbesondere drei Ansätze, die sich diesem Problem widmen, vorgestellt. Dabei herrscht unter diesen Ansätzen Einigkeit darüber, dass nOCD-Algorithmen, also Community-Detection ohne überlappende Communities am besten für dieses zeitkritische Feld geeignet ist. Dennoch sind die drei vorgestellten Algorithmen in ihren Funktionsweisen grundverschieden. So basiert HGN auf dem globalen Attribut der Modularität, DLCD-CCE schafft hingegen eine Basis für die Paralellisierung dieser Aufgabe auf lokaler Ebene und PSA lässt lokale und globale Attribute zusammen arbeiten, um möglichst ausgeglichene Communities zu schaffen. All diesen Ansätzen liegt die Gemeinsamkeit zugrunde, dass sie das Potenzial der Community-Detection auszunutzen möchten, um Ordnung in die Wirren des Internet of Things zu bringen.
Eine solche Ordnung ist mit der Zunahme der Geräte im Internet of Things ein nützliches Werkzeug, welches einen großen Einfluss auf unser zukünftiges Leben haben könnte. So könnte sie zum Beispiel dafür genutzt redundante Sensorendaten herauszufiltern, um nicht benötigte Sensoren abzuschalten und somit eine höhere Energieeffizienz und verbesserte Kommunikation zu gewährleisten.
VI. Referenzen
- Jain, A. K., & Murty, M. N. (01-SEP-1999). Data clustering: A review. ACM Comput. Surv.
- Li, Y., Xia, H., Zhang, R., Hu, B., & Cheng, X. (2020). A Novel Community Detection Algorithm Based on Paring, Splitting and Aggregating in Internet of Things. IEEE Access, 8, 123938–123951. https://doi.org/10.1109/ACCESS.2020.3006029
- Karyotis, V., Tsitseklis, K., Sotiropoulos, K., & Papavassiliou, S. (2018). Big Data Clustering via Community Detection and Hyperbolic Network Embedding in IoT Applications. Sensors (Basel, Switzerland), 18(4), 1205. https://doi.org/10.3390/s18041205
- Xu, X., Hu, N., Trovati, M., Ray, J., Palmieri, F., & Pandey, H. M. (2020). DLCD-CCE: A Local Community Detection Algorithm for Complex IoT Networks. IEEE Internet of Things Journal, 7(5), 4607–4615. https://doi.org/10.1109/JIOT.2019.2960743
- Newman, Mark E. J., & Girvan, M. (2004). Finding and Evaluating Community Structure in Networks. Physical Review, 69(026113).
- Blondel, V. D., Guillaume, J.-L., Lambiotte, R., & Lefebvre, E. (2008). Fast unfolding of communities in large networks. J. Stat. Mech. https://doi.org/10.1088/1742-5468/2008/10/P10008