Datensätze für Multilayer-Netzwerke
| Paul Winter | Sven Farwig | ||
|---|---|---|---|
| RWTH Aachen University | RWTH Aachen University | ||
| paul.winter@rwth-aachen.de | sven.farwig@rwth-aachen.de |
1. Abstract
Das Gebiet der Overlapping Community Detection in Graphennetzen befasst sich mit dem Suchen von Zusammenhangskomponenten (sog Communities) in gerichteten oder ungerichteten Graphen, deren Knoten alle ein oder mehrerer gemeinsamer Kriterien genügen.
Aktuelle Anwendungen erfordern jedoch immer öfter, dass Daten mehrerer Beziehungsebenen gleichzeitig berücksichtigt werden Ein Beispiel sind die gleichzeitige Betrachtung mehrerer sozialen Netzwerken, bei denen Benutzer nicht nur in einer Ebene/Netzwerk Freunde (Nachbarknoten) haben, sondern auf mehreren Verschiedenen darunter. Für solche Anwendungsfälle existieren sog. Multilayer Graphen, welche es erlauben dataillierte Communities Layer-übergreifend zu finden, und so Aussagen über den Graphen zu treffen
Leider ist die Analyse von Multilayer Graphen sehr rechenintensiv und bedarf daher speziell angepasster Algorithmen, da bisherige Methoden nicht oder nur teilweise funktionieren.
Dieses Subgebiet der Graphenalgorithmen wurde deshalb in der jüngeren Vergangenheit bereits ausgiebig untersucht.
In diesem Paper werden wir versuchen, einen Überblick über die Eigenheiten und Besonderheiten der Multi-Layer Netzwerke zu geben. Darüber hinaus werden wir uns auch mit Faktoren wie Gütekriterien sowie den Herausforderungen im Umgang mit diesen vielschichtigen Datensätzen beschäftigen.
Keywords
Community Detection, Overlapping Communities, Multilayer, OCD, Multilayer Networks
Inhaltsverzeichnis
Einleitung
Die Netzwerktheorie als Werkzeug hilft dabei die Struktur von Graphen und den ihnen zugrunde liegenden Systemen, wie man sie zum Beispiel aus der Soziologie, Biologie oder aus dem Transportwesen kennt, zu erforschen (Newman 2018) Dabei hat sich das Suchen und Analysieren von Communities, also Gruppierungen von überdurchschnittlich eng zusammengehörigen Knoten, als fruchtvoll erwiesen. Durch vertiefte Erforschung aktueller Single Layer Graphen hat man jedoch feststellen müssen, dass die Beschränkung des Informationsgehaltes auf die Analyse eines einschichtigen Netzwerkes ohne Klassifizierung unterschiedlicher Knoten immer öfter nicht ausreicht, um die gewünschte Informationstiefe zu erreichen, oder falsche Ergebnisse liefert(Papalexakis et al. 2013). Daher bedarf es sogenannter Multi Layer Netzwerke, welche in der Lage sind, zwischen einzelnen Schichten des Netzwerkes Layer-übergreifende Communities zu finden. Dabei können einzelne Layer zur ordinalen Gliederung des Graphen in Knoten und Kanten unterschiedlichen Typs dienen (wie zum Beispiel in einem Transport-System Kanten, die eine Autoverbindung darstellen, nicht mit Luftverkehrs-Kanten gleichgesetzt werden sollten). Darüber hinaus gibt es aber auch noch die Möglichkeit, den einzelnen Layer eine temporale Komponente zuzuordnen, welche es erlaubt, Aussagen über die Entstehung auffindbarer Communities zu treffen.
So konnte man unter Einsatz von MLN’s (Kivelä et al. 2014; Boccaletti et al. 2014) ultimativ der Lösung zweier fundamentaler Probleme der Community Suche (Hierachische Community Strukturen, überlappende Communities) präsentiert von Lancichinetti et al. (2009) bedeutend näher gekommen werden.
Verwandte Arbeiten
Diese Arbeit basiert zu großen Teilen auf der Arbeit “A survey of community detection methods in multilayer networks” von Xinyu Huang, Dongming Chen, Tao Ren und Dongqi Wang.
Methodik
Graphennotation
Notation
Dabei sind die Knoten \(v_{x}\) und \(v_{y}\) durch eine Kante verbunden, wenn für die Kante \(w_{xy} \ge 0\) gilt mit \(w_{xy} \in E\).
Der Grad eines Knoten \(v_{x}\) ist dabei definiert als \(d_{x} = \sum\limits_{y=1}^n {w_{xy}}\), also die Summe aller Kantengewichte der zu \(v_{x}\) adjazenten Knoten(auch genannt Nachbarn von \(v_{x}\)).
Jeder Knoten kann sowohl Intra-Layer Kanten besitzen, also Kanten zu Nachbarknoten der selben Layer, als auch Inter-Layer Kanten, welche zu Knoten in anderen Layer verbinden.
Bevor nun die für das restliche Paper verwendeten, Notationen für MLN Netzwerke erklärt werden, muss eine kurze Unterscheidung getroffen werden.
So gibt es Multilayernetzwerke, welche auf allen Layer dieselbe Knotenmenge teilen und sich nur in ihren Kanten (innerhalb der Layer und über diese hinweg) unterscheiden. Diese werden in der Fachliteratur gängig “Multiplex Netzwerke” genannt, und ihnen widmet sich wegen ihrer Vielseitigkeit und wohlerforschtheit der Großteil dieses Papers.
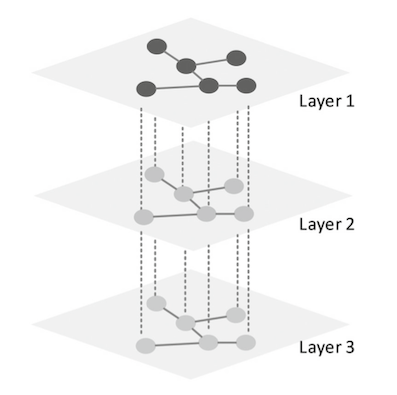
Multiplex Netzwerk - Gleiche Knotenmenge auf allen Layer - Huang et. al 2021
Darüber hinaus gibt es Abwandlungen und Variationen davon (Temporale Netzwerke, K-Partite Netzwerke), welche nicht dieser Einschränkung unterliegen, aber auch dadurch an Vielseitigkeit und der Fähigkeit, mit aktuellen Methoden gut berechenbar zu sein, einbüßen. Ihnen werden wir uns im weiteren Verlauf des Papers eher nicht widmen, aber sie sollten der Vollständigkeit halber Erwähnung finden.

K-partite Netzwerke - Keine Interlayer Kanten und unterschiedliche Knotenmenge auf allen Layer - Huang et. al 2021
Es gibt mehrere Notationen, die versuchen Multiplex Netzwerke (Im Folgenenden mit MLN abgekürzt) zu definieren. Eine sehr informationsreiche Variante aber auch einfach zu verstehende ist die Notation von Boccaletti et al. (2014)
Man erkennt hier, dass Boccaletti ein Multiplex Netzwerk als ein Netzwerken, bestehend aus Netzwerken, definiert. So erkennt man, dass jede Layer als ein eigenes Single-Layer Netzwerk angelegt ist, und erst durch die Menge $C$ kommt es zu Interlayer Kanten. Dieses Modell ist sehr einfach, doch es reicht aus, um die Bedeutung eines sehr wichtigen Werkzeugs motivieren zu können. Gemeint ist die Supra-Adjazenzmatrix.
Supra-Adjazenzmatrix
Ein beliebtes Werkzeug, um Graphen zu verstehen sind Adjazenzmatrizen, welche die Kanten zwischen den \(n\) Knoten darstellen indem eine \(n*n\) Matrix erstellt wird und \(A_{i,j} = 1\) gilt, falls \(i\) und \(j\) eine Kante besitzen.
Nun ist die Supra-Adjazentmatrix eine Erweiterung dieser Adjazentmatrizen wobei \(A_{1},A_{2},A_{3},...,A_{n}\) die einzelnen Adjazentmatrizen der Layer \(1,...,L\) darstellen, welche in einer Matrix im folgenden Angeordnet sind:
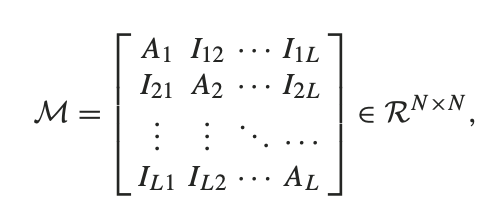
Eine Supra-Ajzazentmatrix - Huang et. al 2021
Ein wichtiger Vorteil dieser Supra-Adjazenzmatrizen ist, schnell eine Zuordnung der Kanten zwischen Layer (Interlayer-Kanten) zu erreichen, welche man oberhalb und unterhalb der Diagonalen finden kann, aber auch auf Kanten innerhalb einer einzelnen Layer (Intralayer-Kanten) zu erlauben.
Eine weitere Forschungs Domäne, in dem Bereich der Multilayer-Netzwerke sind darüber hinaus k-partite Netzwerke. Diese haben als Besonderheit, dass sie keine Intra-Layer Kanten besitzen, sondern nur Inter-Layer Kanten Knoten miteinander verbinden.
Auf sie wird wegen ihrer Eigenschaft, dass sie meist nicht die Anforderungen der äquivalenten Knotenmengen erfüllen, nicht weiter in diesem Paper eingegangen, aber sie sollten dennoch Erwähnung finden, da sie durchaus wichtige Einsatzgebiete besitzen.
Features von MLN Graphen
Centrality
Es existieren mehrere Eigenschaften von Netzwerken, welche in der OCD Analyse betrachtet werden. Eine der häufigsten dieser Merkmale ist die “Graph-Centrality”. Diese wird genutzt um die Bedeutungskraft einzelner Knoten für das Gesamtnetzwerk zu ermitteln, indem die Wichtigkeit dieser Knoten für die Umliegende Nachbarknoten analysiert wird (Grad-Centrality, PafeRank, Closeness-Centrality). Dieses Thema ist auch bereits sehr gut erforscht für Single Layer Netzwerke, und oft wird dabei der Grad jedes Knotens betrachtet. Dies führt jedoch zu mehreren Problemen, bei dem Versuch diese Definition auf MLN Netzwerke anzuwenden. So kann ein Knoten in einer Layer mit einem Anderen verbunden sein, jedoch in einer Anderen isoliert sein. Ist dieser Knoten nun als Nachbar des Ursprungsknotens zu werten oder nicht? Abhilfe verschaffen kann hier die Herangehensweise den Grad als Vektor aufzufassen statt als einzelnen Wert, und so das Problem wieder auf Centrality im Single Layer Graphen isoliert betrachten zu können.Auch verbreitet ist die Methode und einen Schwellenwert $\lambda$ zu verwenden, welcher definiert, dass die Verwanschaft von Knoten in einer Submenge der Layer bereits ausreicht, um sie am MLN als “verwandt” zu bezeichnen.
Die größte Achilles-Ferse der Centrality in MLNs stellt jedoch die fehlende Unterscheidungs Möglichkeit zwischen Intra-Layer Nachbarn und Inter-Layer Nachbarn dar. So können Inter-Layer Nachbarn nicht für die Berechnung der Centrality verwendet werden, da eine zweifelsfreie Zuordnung zu dem passenden Knoten in der passenden Layer nicht eindeutig wäre. Dieses Problems wurde bereits in den letzten Jahren erforscht, allerdings würde ein detaillierter Einstieg hier den Rahmen sprengen. (Huang et al., 2021)
Correlation
Darüber hinaus kann speziell in Multilayer Netzwerken durch Kanten zwischen Knoten auf mehreren Layer eine Korrelation abgeleitet werden, welche die Ähnlichkeit der Layer mit einbezieht, diese Metrik nennt man “Correlation” Hierbei werden die Kanten der einzelnen Knoten in den unterschiedlichen Layer auf Schnittmengen hin überpfüft und so die Aussagekraft einer einzelnen Kante jedes Knotens bestimmt. Die Mathematische Berechnung der Correlation, soll dem Leser hier erspart bleiben, da sie durchaus sehr komplex ist, insbesondere in einem MLN Graphen. Dennoch lohnt es sich Correlation zu erwähnen, da sie dazu genutzt werden Können MLN Community Entdeckungs Algorithmen zu optimieren.(Huang et al., 2021)
Evaluations-Metriken
Die Problemstellung der Community Detection Algorithmen versucht einen Multilayer Graphen in disjunkte zusammengehörige Module \(C_{1},...,C_{n}\) zu unterteilen, wobei ein Modul \(C_{n}\) eine Community also eine Gruppe an Knoten bezeichnet, die in sich stärker miteinander verbunden sind, als außerhalb der Community. Wie gut ein Algorithmus dies schafft, und welchen Kriterien eine richtige Lösung zu unterliegen hat, versuchen die nachfolgenden Metriken und Evaluationsmechanismen zu bewerten.
Modularity und Modularity-Density
Mit dem Maß der Modularität gelingt es, für Graphen zu beschreiben, wie viele spärlich miteinander verbundene Zusammenhangskomponenten in diesem existieren. Es ist eine sehr beliebte Qualiätsfunktion für Communities, und wird deshalb auch in der sog. Louvain Methode zur Community Entdeckung eingesetzt. Die Idee ist, je enger jeder Punkt mit jedem anderen verbunden ist, desto größer ist das Maß der Modularität. Diese Metrik existierte ursprünglich nur für Single Layer Graphen, wurde aber auch auf Multilayer Graphen erweitert.
Ein Problem von Modularität ist allerdings ein Umstand, der als “Auflösungsschranke”(Resolution-Limit) bezeichnet wird. Damit ist die wachstende Ungenauigkeit beim Erreichen einer gewissen unteren Schranke an Knoten innerhalb einer Community gemeint, welche insbesondere bei großen Netzwerken auftritt (häufig ein Problem von MLN Netzwerken).
Als Alternative zu Modularität wurde deshalb “Modularity-Density” entwickelt, welche die Probleme der Auflösungs-Schranke löst, indem es den den Grad einer Community nicht, wie bei Modularität mit einem Random Graphen vergleicht und so klassifiziert, sondern direkt den Grad jedes Knotens aufteilt in Nachbarn innerhalb und außerhalb der Community und diese zwei Grade dann in Relation setzt.
Surprise
Surprise bedient sich einer Herangehensweise der Stochastik. So berechnet dieses Maß die Wahrscheinlichkeit, dass eine Partition des zu analysierenden Graphen in Communities auftritt, verglichen mit einer zufälligen Partitionierung des Graphen mithilfe eines Null-Models(Ein Graph mit selber Knotenmenge und Kantenanzahl wie der Eingangsgraph, aber randomisierter Kantenmenge). Da es nicht, wie Modularität, direkt von einer Anzahl an Kanten ausgeht und auf dessen Existenz aufbaut, kann es auch das Problem der Auflösungsschranke umgehen. Durch verschiedene Maximierungsstrategien von Surprise können darüber hinaus auch in komplexe, Netzwerken Community Strukturen entdeckt werden.
Purity, Precision, Performance und NMI
Es gibt Möglichkeiten einen Algorithmus zur Community Detection zu Benchmarken, indem dieser auf einem vorher generierten Netzwerk mit bekannten Communities (Ground Truth Netzwerk) simuliert wird. Dieses kann entweder aus der realen Welt entstammen oder ein synthetisches Netzwerk sein, wie zum Beispiel der LFR benchmark (Huang et al., 2021). Dafür eignet sich NMI. Es vergleicht den Informationsgehalt einer Partition mit dem der Ground-Truth Partition, und gibt so eine Aussage darüber, wie “genau” die Einordnung des Graphen wirklich ist. Da NMI allerdings für z Communities \(O(z^2)\) Laufzeit benötigt, insbesondere auf Multilayernetzwerken, wurden auch andere beliebte Metriken entwickelt, um auch auf großen Netzwerken Partitionen zu benchmarken, darunter Prexision und der sog Rand Index (ARI). Diese beruhen darauf, einzig und allein die Falsch Positiv - Falsch Negativ - Wahr Positiv und Wahr Negativ zugewiesenen Knoten abzuwägen, und daraus zu errechnen, wie genau eine Community Partitionierung gefunden wurde.
Algorithmen
Um Communities in Multilayer-Netzwerken zu finden, macht es einen Unterschied, welches der zuvor vorgestellten Multilayer-Netzwerke man hat.
Multiplex-Netzwerke werden meist in Singlelayer-Netzwerke umgewandelt (“Layer-Flattening”), indem entweder wenn in
mindestens einer Schicht eine Kante zwischen zwei Knoten vorhanden ist, auch im resultierenden
Singlelayer-Netzwerk eine Kante zwischen den Knoten besteht, oder die Kantengewichte im
Singlelayer-Netzwerk der Anzahl der Kanten zwischen zwei Knoten entspricht (Huang et al., 2021),
das ist auch die Methode, die wir für unsere Datensätze verwendet haben.
Für andere Arten von Multilayer-Netzwerken ist diese Methode auch anwendbar, aber wegen den unterschiedlichen Knotenmengen in den verschiedenen Schichten nicht so intuitiv anwendbar wie für Multiplex-Netzwerke. Der Vorteil dieser Methode ist, dass sich auf die resultierenden Singlelayer-Netzwerke die traditionellen Algorithmen zur Entdeckung von Communities anwenden lassen. Der Nachteil ist jedoch, dass dadurch die Informationen innerhalb der verschiedenen Schichten zur Community Entdeckung verloren gehen.
Eine weitere Möglichkeit ist es, auf jeder Schicht nach Communities zu suchen und die Schichten im nachhinein zusammenzufügen(“Layer-Aggregation”). Diese Variante klingt besonders sinnvoll für Temporale Netzwerke, da die benachbarten Schichten dort häufig sehr ähnlich zueinander sind. Allerdings benötigt die Methode \(2^L\) Vergleiche, wobei \(L\) der Anzahl der Schichten entspricht, außerdem hat die Methode auf synthetischen Datensätzen nicht so genaue Ergebnisse geliefert, wie andere Methoden, deshalb ist das Zusammenfügen nicht empfohlen (Huang et al., 2021).
Die dritte Möglichkeit ist es, im Multilayer-Netzwerk direkt nach Communities zu suchen. Dafür braucht es allerdings neue oder angepasste Algorithmen, deren Erforschung zum jetzigen Zeitpunkt noch nicht weit fortgeschritten ist. Die meisten dieser Algorithmen laufen nur auf Multiplex-Netzwerken und haben häufig eine sehr schlechte Laufzeit.
Evaluation
Im Nachfolgenden haben wir mithilfe des Extended Speaker Listener Label Propagation Algorithmus die Communities des ersten, des zweiten, des dritten und des vierten und fünften Buches von Game of Thrones einzeln bestimmt und im Anschluss alle Bücher in einem Graphen vereint, indem alle Kantengewichte zwischen zwei Knoten über alle Bücher hinweg aufaddiert wurden. Somit haben wir ein temporales Netzwerk über 4 Schichten vorliegen und es im Anschluss zu einer Schicht zusammengestaucht. Dabei zählt jede Interaktion zwischen zwei Charakteren, wenn ihre Namen innerhalb von 15 Wörtern zusammen erwähnt werden.
Game of Thrones Buch 1
Im ersten Buch gibt es nur drei große Communities, Daenerys Targaryen bildet den wichtigsten Punkt in der roten Community, Jon Snow den Wichtigsten in der hellblauen Community und Eddard Stark den Wichtigsten in der gelben Community. Bran und Robb Stark sind zwei große Punkte zwischen der Community von Jon Snow und der von Eddard Stark, auch Theon Greyjoy liegt in dem Bereich. Später in der Analyse noch sehr relevante Charaktere wie Arya Stark oder Tyrion Lannister gehören der großen gelben Community an.
Game of Thrones Buch 2
Im zweiten Buch bilden Jon Snow und Daenerys Targaryen immer noch den wichtigsten Punkt in ihrer roten und hellblauen Community. Arya Stark hat sich aus der gelben Community in ihre eigene braune Community abgespalten. Robb Stark ist jetzt auch ein vollständiger Teil der gelben Community, während Bran Stark seine eigene dunkelblaue Community hat und auch Theon Greyjoy ist jetzt Teil einer neuen Community, ohne Verbindung zur Community von Jon Snow.
Game of Thrones Buch 3
Auch in Buch 3 haben Daenerys Targaryen und Jon Snow immer noch ihre eigenen Communities oben und unten. Arya Stark bildet immer noch den größten Punkt in der braunen Community. In diesem Buch bildet Robb Stark den größten Punkt der dunkelblauen Community und hat sich damit von der gelben Community abgespalten. Bran Stark ist jetzt in die Mitte der blauen, der gelben und der Community von Jon Snow gerückt. Zusätzlich hat sich eine lilane Community rund um Davos Seaworth und Stannis Baratheon, der vorher noch Teil der gelben Community war, aufgetan.
Game of Thrones Buch 4 und 5
Buch 4 und 5 haben wir in eine Schicht zusammengeschoben, da die meisten der alten Charaktere in einem der beiden Bücher nicht vorkommen, dadurch ließ sich der zeitliche Verlauf nicht mehr so gut nachvollziehen. Auch hier bildet Daenerys Targaryen wieder den größten Punkt der roten Community und ist damit über alle fünf Bücher hinweg der wichtigste Teil einer abgetrennten Community. Auch Arya Stark ist immer noch der wichtigste Punkt der braunen Community, aber ist weiter abgetrennt von allen anderen Charakteren als in den Büchern davor. Nachdem Theon Greyjoy in Buch 3 nicht so relevant war, ist er jetzt wieder einer der zwei wichtigsten Punkte in der Arya Stark am nahen grünen Community, andere Charaktere mit dem Namen Greyjoy bilden allerdings eine eigene Community. Tyrion Lannister ist immer noch Teil der gelben Community und auch der wichtigste Punkt dort, aber ein großer Teil der gelben Community ist jetzt Teil der hellblauen Community, der auch Jon Snow immer noch angehört, die Verbindung zwischen denen stellt Stannis Baratheon dar. Dieser wird in Buch 4 und 5 erwähnt und stellt deshalb eine Verbindung innerhalb der Community her, dabei ist unser Ergebnis wahrscheinlich nicht so gut, Jaime und Cersei Lannister sollten eher eine eigen Community bilden als Teil der Community von Stannis und Jon zu sein.
Game of Thrones Buch 1 bis 5
Wenig überraschend sind über alle Bücher hinweg die rote Community von Daenerys Targaryen und die hellblaue Community von Jon Snow wieder mit dabei. Auch die gelbe Community mit Charakteren wie Tyrion Lannister und Eddard Stark ist dabei und bildet mehr als 25% aller Charaktere, überraschenderweise ist aber auch Arya Stark Teil dieser Community, obwohl sie nur im ersten Buch Teil dieser Community war und in allen anderen ihre eigene Community um sich gebildet hat. Bran Stark ist wieder Teil der blauen Community, wie in Buch 2, in Buch 1 und 3 stand er eher zwischen verschiedenen Communities. Auch Teil der blauen Community ist Theon Greyjoy, der in keinem Buch in derselben Community wie Bran war. Robb Stark befindet sich zwischen der blauen und der gelben Community, nachdem er in den 2 und 3 jeweils einmal Teil der gelben und der blauen Community war.
Die Informationen über die Veränderung über die Bücher hinweg geht in einem gesamtheitlichen Graphen verloren. Die Charaktere stehen am Ende an einem Punkt, der einen Mittelwert über die Bücher hinweg ergibt, an dem sie aber vielleicht nur in einem Buch standen, wie bespielsweise Arya Stark, oder sogar nie am entsprechenden Punkt, wie beispielsweise Theon Greyjoy.
Wir haben in unserer Auswertung keine Intralayer-Kanten verwendet. Das lag hauptsächlich daran, dass wir nicht in der Lage waren, diese Intralayer-Kanten zu verwerten, da uns der Zugriff auf entsprechende Algorithmen fehlte. Intralayer-Kanten sind aber eine sehr wichtige Eigenschaft von Multilayer-Netzwerken. Wir hatten auch nicht die Möglichkeit einen Algorithmus über ein echtes Multilayer-Netzwerk laufen zu lassen, deshalb haben wir alle vier Schichten zu einer zusammengefügt und über jede der vier Schichten nochmal einzelnd den Algorithmus laufen lassen. Die Communities der vier Schichten mithilfe der Layer-Aggregation zu einem Ergebnis zusammenzufügen hätte die Möglichkeit gebracht diese beiden Methoden miteinander zu vergleichen, aber dazu fehlte uns leider auch die Möglichkeit.
Ausblick und Anwendungsgebiete
Es ist klar, dass Multilayernetzwerke vielschichtige Einsatzgebiete haben, welche auch noch weit über die von Single Layer Netzwerken hinausgehen.
Einige Beispiele sollen hier genannt werden:
Das heutige Transportwesen lebt von der Vielschichtigkeit der Verkehrsmittel und Wege und ihren Überschneidungen und gegenseitigen Komplementierungen. Es ist von sehr großem Interesse, optimale Wege und Communities in diesen Netzwerken zu finden, um das Transport und Verkehrsverhalten besser verstehen zu können und als Folge optimalere Auslastungen der Routen zu erreichen, oder auch gezielten Ausbau der Infrastruktur betreiben zu können. Dafür eignen sich allerdings Multilayernetzwerke ganz besonders, da jede Form des Transports (Luft, Schiene, Straße) auf einer eigenen Layer repräsentiert und gewichtet werden kann.
Auch in sozialen Netzwerken werden Community Detection Ansätze schon seit Längerer Zeit erforscht. Jedoch ermöglichen es erst Temporale-Multilayer Netzwerke, das Entstehen von Communities über die Zeit hinweg verstehen zu können, indem durch Interlayer-Kanten die Beziehung zwischen den einzelnen Personen über eine längere Zeit hinweg modelliert werden kann.
Aber auch in der Biologie und Medizin werden Multilayer-Netzwerke immer öfters verwendet um die komplexen Strukturen und Interaktionen einzelner Protein-Gruppen miteinander zu analysieren. Dabei gibt es Proteinkomplexe und Proteinfunktionen, wobei die Unterscheidung beider Proteinarten das Forschungsziel darstellt.
Auch in der Gehirnforschung werden Ansätze der Multilayer Netzwerke genutzt um zum Beispiel die Gruppierung und Entwicklung bestimmter Cluster von Synapsen über einen gewissen Zeitraum hinweg (mehrere Layer) zu analysieren und so Rückschlüsse auf Krankheiten wie Alzheimer ziehen zu können.
Man kann also sagen, dass insbesondere in komplexen Datenumgebungen sehr schnell der Punkt erreicht sein kann, bei dem die reine Informationsmenge eines Single Layer Networks unzureichend wird, und deshalb Multi-Layer Netzwerke als Abhilfe eingesetzt werden.
Dennoch bedarf es auf dem Gebiet der Multilayer Graphen noch weiterer Forschung, da insbesondere bei Multilayernetzwerken mit besonders vielen Kanten bestehende Algorithmen sehr schnell in ihrer Leistung und Genauigkeit einbüßen. (Huang et al., 2021)
Referenzen
- Huang, X., Chen, D., Ren, T., & Wang, D. (2021). A survey of community detection methods in multilayer networks. Data Mining and Knowledge Discovery, 35(1), 1–45. https://doi.org/10.1007/s10618-020-00716-6