Evaluationskriterien für Multilayer-Netzwerke
| Denis Baykan |
|---|
| RWTH Aachen University |
| denis.baykan@rwth-aachen.de |
| Justus Peretti |
|---|
| RWTH Aachen University |
| justus.peretti@rwth-aachen.de |
| Simon Stricker |
|---|
| RWTH Aachen University |
| simon.stricker@rwth-aachen.de |
Abstract
Wir Menschen kommunizieren online heutzutage über mehrere Plattformen. Stellt man diese Kommunikation nur in einem Singlelayer-Netzwerk dar, geht die Information verloren, auf welcher Plattform die Kommunikation stattfand. Dem gegenüber sind Multilayer-Netzwerke dafür geeignet, die Art der Beziehung zwischen zwei Knoten festzuhalten und das Netzwerk in Layer, im Falle der digitalen Kommunikation in die Plattformen, aufzuteilen. Neben der digitalen Kommunikation finden Multilayer-Netzwerke in Gebieten wie der Ökonomie, den Sozialwissenschaften und der Neurowissenschaft ihre Anwendung, da sie neue Lösungsansätze für bekannte Probleme bieten. Gleichzeitig weisen sie jedoch auch eine erhöhte Komplexität gegenüber Singlelayer-Netzwerken auf und können nach den unterschiedlichsten Kriterien evaluiert werden. Zur Analyse von Multilayer-Netzwerken müssen bekannte Evaluationskriterien von Singlelayer-Netzwerken um den Vergleich zwischen den Schichten erweitert werden, so zum Beispiel bei der Zentralität und der Ähnlichkeit. Diese Kriterien werden im Folgenden anhand eines Beispielnetzwerks erläutert und konkret auf das Beispielnetzwerk angewendet. Unsere Arbeit soll somit einen Beitrag zur Bestimmung und Erforschung von Communities leisten, die Bedeutung jener Kriterien hervorheben und beispielhaft anhand von ausgewählten Kriterien vorführen, wie eine mögliche Evaluation erfolgen könnte. Somit liefert unsere Arbeit eine Rekapitulation von bekannten Konzepten an einem vorhandenem Beispielnetzwerk und zeigt die schwache Korrelation zwischen den Layern des Beispielnetzwerks auf.
Inhaltsverzeichnis
1. Einleitung
Multilayernetzwerke bieten einen entscheidenden Informationsgewinn. Diesen möchten wir anhand eines Beispielnetzwerks, das in Layer unterteilt ist, verdeutlichen. Die Erweiterung vom Konzept Singlelayer-Netzwerke um Layer bietet eben den Informationsgewinn, der in der Analyse nur erzielt werden kann, wenn Evaluationskriterien, konkret in unserer Arbeit die Zentralität und die Ähnlichkeit, an das Konzept Multilayernetzwerk angepasst werden. Denn es ist häufig nicht nur interessant zu wissen, ob ein Knoten ein Hub ist oder wie hoch sein Knotengrad ist, sondern auch welche Rolle er innerhalb der einzelnen Layer einnimmt. Dies ist unter anderem zur Ermittlung von zentralen Personen in den sozialen Medien (Zafarani et al., 2014) oder zentralen Gehirnregionen zur Datenverarbeitung (van den Heuvel & Sporns, 2013) von Bedeutung.
Zudem ist auch die Entwicklung des Netzwerkes vor allem im Bezug auf schon vorhandenen Strukturen wichtig.
Denn es können anhand vorhandener Strukturen andere Layer nicht nur rekonstruiert, sondern auch für potentiell noch entstehende Eigenschaften genutzt werden, bspw. um herauszufinden, wie hoch die Wahrscheinlichkeit für eine Entstehung von Verbindungen durch die eines anderen Layers ist oder um die Existenz von strukturellen Eigenschaft in mehreren Layern erklären zu können.
Daher ist unsere Arbeit notwendig, um Zentralität und Anwendung besser verstehen und auf Multilayernetzwerke anwenden zu können.
Denn wir wollen mit unserer Arbeit beispielhaft zeigen, wie ein Multilayernetzwerk anhand von Evaluationskriterien analysiert werden kann.
Dementsprechend werden im Folgenden die Methodiken bei der Analyse erläutert, wobei besonders auf die mathematische Definition der Kriterien eingegangen wird. Daraufhin werden die Ergebnisse unserer Anwendung auf das Beispeilnetzwerk mittels Diagrammen präsentiert und anschließend diskutiert. Abschließend werden wir unsere Ergebnisse kurz zusammenfassen.
2. Verwandte Arbeiten
Die Arbeit “Structural measures for multiplexnetworks” von Federico Battiston, Vincenzo Nicosia und Vito Latora hat einen großen Beitrag zur erstmaligen Definition von verschiedenen Evaluationskriterien von Multilayernetzwerken geleistet (Battiston et al., 2014) und verschiedene Ansätze zur Analyse von grundlegenden Knoteneigenschaften, lokalen Strukturen, z.B. Dreiecken, und der Zentralität, vor allem Eigenvektorzentralität vorgestellt. Wir beziehen uns in unserer Arbeit vor allem auf die Abschnitte bezüglich der Knotengradeigenschaften und des participation coefficient. Ebenso relevant ist die Arbeit “The structures and Dynamics of multilayer networks”, welche vor allem die Struktur von Multilayernetzwerken, sowie die Themen Robustheit und ihre Anwendungen behandelt, aber sich in einem Abschnitt dem Thema Korrelation zwischen Layern widmet. In unserer Arbeit nehmen wir Bezug auf den dort vorgestellten “Kendall coefficient” (Boccaletti et al., 2014). Außerdem ist der Ähnlichkeitsabschnitt vor allem von Amir Mahdi Abdolhosseini-Qomi et. al wissenschaftlicher Ausarbeitung beeinflusst worden, welche sich beispielsweise mit der Ähnlichkeit zweier verschiedener Layer beschäftigen und verschiedene mathematische Konzepte für die Bestimmung und mathematische Realisierung jenes Evaluationskriteriums einführen (Abdolhosseini-Qomi et al., 2020). Dabei beziehen wir uns vor allem auf die mathematischen Aspekte jener Arbeit, die wir unserer Arbeit anwenden und visualisieren.
3. Methodik
3.1 Zentralität
Zentralität dient als Maß zur Bestimmung der Wichtigkeit eines Knoten in Relation zu anderen Knoten im Netzwerk und der gesamten Netzwerkarchitektur (van den Heuvel & Sporns, 2013). In der Vergangenheit wurden verschiedene Ansätze zur Quantifizierung der Zentralität entwickelt, bspw. Knotengrad-, Eigenvektor-, “betweenness-”, “closeness-” und “pagerank-Zentralität”. Wir beschränken uns im Folgenden auf die Knotengradzentralität. Mithilfe der Knotengradzentralität lassen sich auch Hubs finden, welche die wichtigsten, zentralsten Knoten eines Netzwerks sind (van den Heuvel & Sporns, 2013).
3.1.1 Knotengrad
Im folgenden Abschnitt wollen wir die Knotengradzentralität bestimmen. Dazu definieren wir unterschiedliche Arten von Knotengraden.
Der Grad \(k_i^{[\alpha]}\) des Knoten \(i\) in Layer \(\alpha\) kann mittels der Summe \(k_i^{[\alpha]} = \Sigma _j a_{ij}^{[\alpha]}\) bestimmt werden, wobei \(a_{ij}^{[\alpha]}\) dem Eintrag in der Adjazenzmatrix des Graphen des zugehörigen Layers \(\alpha\) entspricht; d.h. \(a_{ij}^{[\alpha]} = 1\), wenn eine Kante zwischen den Knoten \(i\) und \(j\) im Layer \(\alpha\) existiert(siehe: Grundlagen im OnlineBuch). Durch aufsummieren der Knotengrade über \(M\) Layer erhält man den overlapping degree: \(o_{i} = \Sigma _{\alpha = 1}^Mk_{i}^{[\alpha]}\) . Darüber hinaus betrachten wir die kumulierte topologische Adjazenzmatrix \(A = \{a_{ij}\}\), wobei
\(a_{ij} = \begin{cases}1 &\text{wenn gilt: } \exists\alpha:a_{ij}=1\\ 0 & \text{andernfalls} \end{cases}\).
Das bedeutet der Eintrag \(a_{ij} = 1\), wenn eine Kante vom Knoten i zu Knoten j in einem der drei Layer existiert. Für den Knotengrad \(k_i\) eines Knoten \(i\) im kumulierten topologischen Netzwerk gilt: \(k_i = \Sigma _j a_{ij}\) (Battiston et al., 2014). Der Knotengrad eines Knoten im kumulierten topologischen Netzwerk bezeichnen wir im Folgenden als kumulierten Knotengrad. Durch den Vergleich zwischen den Layer-degrees und dem overlapping degree bzw. dem kumulierten Knotengrad kann die Zentraliät eines Knoten in einem Layer der Zentralität im gesamten Netzwerk bzw. im kumulierten Netzwerk gegenübergestellt werden. Zentralität messen wir anhand des Knotengrades nach (Wasserman et al., 1994). Darüber hinaus werden in Kapitel vier durch den Layer-degree die Layer untereinander in Relation gesetzt, um zu untersuchen inwiefern die Layer-degree korrelieren.
3.1.2 Correlation coefficient
Die Knotengrade der einzelnen Layer können zusammenhängen. Wenn jeder Knoten, der in Layer \(\alpha\) ein Hub ist, auch in Layer \(\beta\) ein Hub ist, spricht man von maximal-positiv korrelierendem Netzwerken (MP). Im umgekehrten Fall hat der Knoten mit dem größten Knotengrad in einem Layer den kleinsten Knotengrad in Layer \(\beta\). Derartige Netzwerke werden maximal-negativ korrelierend (MN) genannt. Andernfalls hängen die Layer nicht zusammen, wobei solche Netzwerke als nicht-korrelierend “uncorrelated” bezeichnet (UN) werden(Min et al., 2014).
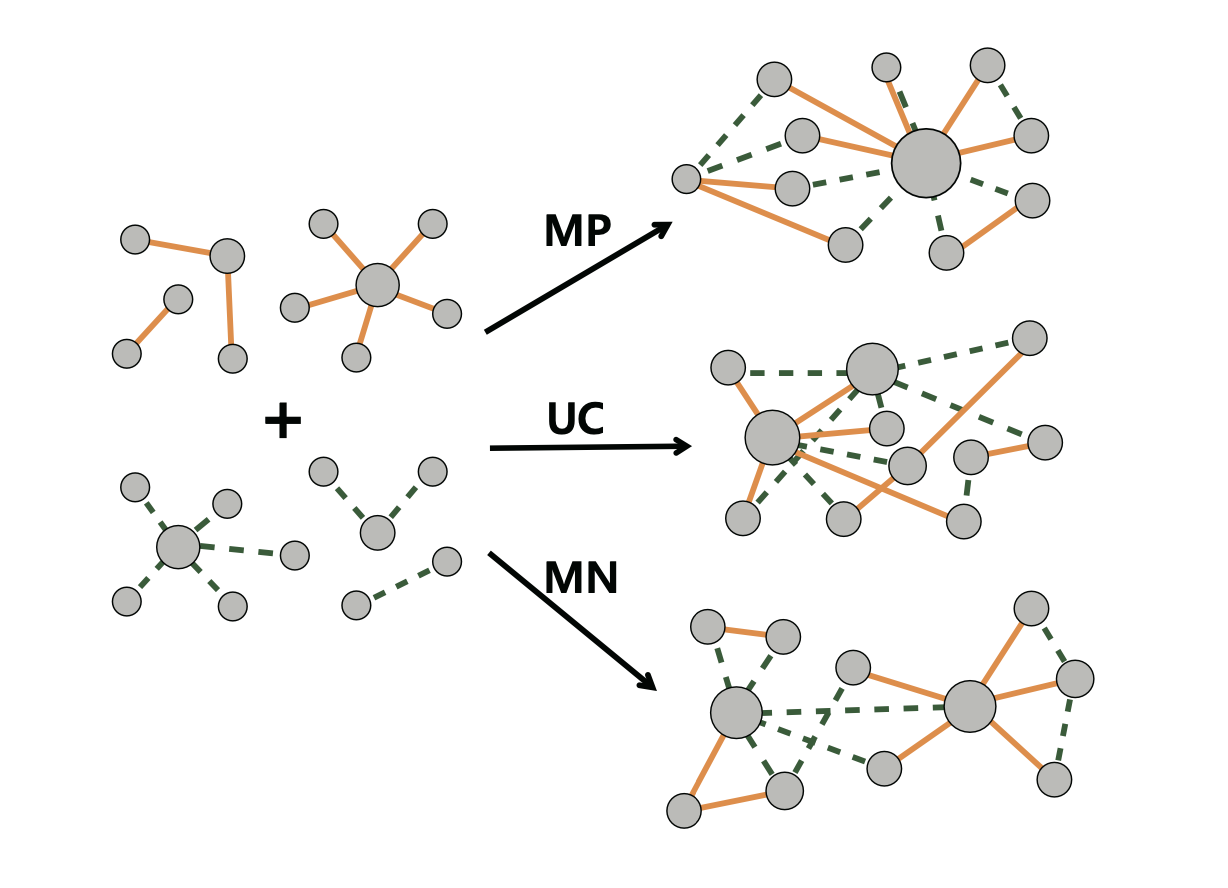 Abbildung 1: Schematische Darstellung von maximal-positiv korrelierenden (MP), maximal-negativ korrelierenden (MN) und nicht-korrelierenden “uncorrelated” (UN) Netzwerken (Min et al., 2014).
Abbildung 1: Schematische Darstellung von maximal-positiv korrelierenden (MP), maximal-negativ korrelierenden (MN) und nicht-korrelierenden “uncorrelated” (UN) Netzwerken (Min et al., 2014).
Um die Korrelation zwischen den Layer-degrees und den kumulierten Knotengrad bzw. overlapping degree genauer quantifizieren zu können, wird im Folgenden der Kendall rank correleation coefficient \(\tau\) betrachtet. Dafür legen wir zunächst fest: Ein Paar von Knoten \(i\) und \(j\) heißt konkordat, wenn ihre Knotengrade in der gleichen Reihenfolge in den zwei Folgen, den nach Größe sortierten Knotengraden, \((x_i^{[\alpha]})\) und \((x_i^{[\beta]})\) auftauchen, d.h. falls \((x_i^{\alpha}-x_j^{\alpha})(x_i^{\beta}-x_j^{\beta}) \geq 0\) gilt. Andernfalls nennt man das Paar diskonkordant. Der Kendall rank correlation coefficient \(\tau\) lässt sich mit folgender Formel berechnen: \(\tau = \frac{n_c-n_d}{n \choose 2} = \frac{2(n_c-n_d)}{n*(n-1)}\) . \(n\) bezeichnet die Anzahl an Knoten, sowie \(n_c\) die Anzahl konkordanter, \(n_d\) Anzahl diskonkordanter Paare. Zudem bestimmt \({n \choose 2}\) die Anzahl an Kombinationen, ein Knotenpaar unter allen Knoten auszuwählen(Boccaletti et al., 2014). Anschaulich gesprochen, ist der Kendall rank correlation coefficient ein Richtwert für die Korrelation zwischen zwei Layern.
3.1.3 Participation coefficient
Ein Indikator für die Verteilung der Knotengrade eines Knoten zwischen den Layer ist der participation coefficient \(P_i\) eines Knoten \(i\) : \(P_{i} = {M \over M -1}* [1- \Sigma _{\alpha = 1}^M({k_{i}^{[\alpha]}\over o_{i}})^2]\) , wobei M für die Anzahl an Layern im Netzwerk steht (Wang et al., 2021). Der participation coefficient nimmt Werte im Intervall [0,1] an und erreicht sein Minimum im Allgemeinen, wenn alle Kanten eines Knoten \(i\) in einem Layer liegen. Er erreicht sein Maximum, falls die Knotengrade \(k_i^{[\alpha]}\) eines Knoten \(i\) über alle Layer gleich verteilt sind. Der overlapping degree zeigt die allgemeine Wichtigkeit eines Knotens anhand der Anzahl an ausgehenden Kanten und der participation coefficient gibt Auskunft über die Verteilung der ausgehenden Kanten eines Knoten über die Layer. Wir wollen alle Knoten nun nach diesen zwei Kriterien klassifizieren. Wir nennen einen Knoten \(i\) konzentriert, falls \(0 \leq P_i \leq 1/3\) gilt, gemischt, falls \(1/3 < P_i \leq 2/3\) gilt und multiplex, falls \(2/3 < P_i\) zutrifft. Zudem wollen wir die Knoten in Hubs und gewöhnliche Knoten einteilen. Dafür würde sich der overlapping degree als Indikator der Zentralität anbieten. Jedoch ist dieser netzwerkübergreifend nicht einheitlich. Denn ein overlapping Degree von 80 ist unserem Beispielnetzwerk sehr groß, sodass man den zugehörigen Knoten einen Hub nennen könnte. In einem Netzwerk von über 5000 Knoten, welches ähnlich dicht vernetzt ist wie unseres, könnte ein Knoten mit einem overlapping degree von 80 jedoch zu den dezentralsten Knoten gehören. Daher betrachten wir für eine höhere Vergleichbarkeit im Folgenden den Z-Score: \(z(o_i) = \frac{o_i - \langle o \rangle}{\sigma_o}\). Hierbei bezeichnet \(\langle o \rangle\) den Durchschnitt und \(\sigma_o\) die Standardverteilung aller overlapping degrees. Als Hubs definieren wir Knoten mit \(z(o_i) \geq 2\) und als gewöhnliche Knoten solche mit \(z(o_i) < 2\) . Dadurch ergeben sich sechs Klassen (Battiston et al., 2014).
3.2 Ähnlichkeit
In diesem Abschnitt wird untersucht, wie ein Netzwerk unter struktureller Ähnlichkeit zweier Layer evaluiert werden kann.
Eigenvektoren einer Adjazenzmatrix treffen Aussagen über die strukturellen Eigenschaften eines Netzwerkes (Lü et al., 2015). Hier werden Verfahren aufgeführt, die mithilfe von Eigenvektoren und Eigenwerten die Vergleichbarkeit und Vorhersehbarkeit von Netzwerken ermöglichen.
3.2.1 Diagonalisierbarkeit der Adjazenzmatrix
Die Adjazenzmatrix eines Multilayer-Netzwerkes G mit N Knoten und M ungerichteten sowie ungewichteten Schichten lässt sich mit \(A^{[\alpha]} = \sum^{N}_{k=1} \lambda^{[\alpha]}_{k}x^{[\alpha]}_{k}x^{[\alpha]^{T}}_{k}\) diagonalisieren,
wobei \(\lambda^{[\alpha]}\) der Eigenwert und \(x^{[\alpha]}_{k}\) der entsprechende orthogonale und normalisierte Eigenvektor von \(A^{[\alpha]}\) sind. Die Notation \(A^{[\alpha]}\) bedeutet,
dass wir die Schicht \(\alpha \in \{1,2,...,M\}\) betrachten (Lü et al., 2015).
Diagonalisierte Adjazenzmatrizen liefern eine einheitlichere Darstellung, was beim Vergleich zweier Adjazenzmatrizen von vorteil ist.
3.2.2 Ähnlichkeit der strukturellen Eigenschaften
Die Ähnlichkeit der strukturellen Eigenschaften zweier Layer eines Netzwerkes können betrachtet werden, damit sind beispielsweise lokale Strukturen wie Dreiecksbeziehungen zwischen Knoten oder aber auch globale wie Hubs gemeint.
Um die Ähnlichkeit mathematisch auszudrücken, definieren wir eine Ähnlichkeitsmatrix mit \(O^{[\alpha, \beta]} = \{o^{[\alpha, \beta]}_{kl}\}\) mit \(o^{[\alpha, \beta]}_{kl} = |x^{[\alpha]^{T}}_{k}x^{[\beta]}_{l}|\) , wobei \(x_{k}\) der Eigenvektor nach k-größtem Eigenwert
der Adjazenzmatrix \(A^{[\alpha]}\) und \(x_{l}\) der l-größte der Adjazenzmatrix \(A^{[\beta]}\) ist.
Darüber hinaus nehmen die Elemente \(O^{[\alpha, \beta]}\) einen Wert im Intervall [0,1] an, wobei gilt: je höher der entsprechende Wert ist, desto ähnlicher sind die strukturellen Eigenschaften. So ist \(O^{[\alpha, \alpha]} = I\), die Einheitsmatrix bei idealer Ähnlichkeit (Abdolhosseini-Qomi et al., 2020).
Damit wäre die Ähnlichkeit von jedem Eigenvektor aus einem Layer zu einem beliebigen anderen berechnet worden. Wir benötigen allerdings ein weiteres Konzept, um Aussagen über die Ähnlichkeit des gesamten Layers zu bestimmen.
Dafür wird nun die Ähnlichkeit mit \(q^{[\alpha, \beta]} = \frac{tr(P_{r}O^{[\alpha, \beta]}P_{c})}{N}\) definiert.
Dabei werden die Zeilen und Spalten so permutiert, dass die Spur der Ähnlichkeitsmatrix \(O^{[\alpha, \beta]}\) maximiert wird.
\(q^[\alpha, \alpha]\) wird stets 1 sein und erneut gilt: je höher der Wert von \(q^{[\alpha, \beta]}\) sein wird, desto ähnlicher sind sich jene Schichten (Abdolhosseini-Qomi et al., 2020).
Somit kann die Ähnlichkeit zweier Schichten näher beurteilt werden.
3.2.3 Weitere Anwendungen der Ähnlichkeit
Das Konzept der Ähnlichkeit findet sich in anderen Eigenschaften eines Netzwerkes wieder, welche wiederum evaluiert werden könnten:
Beispielsweise bei der sogenannten Schichtrekonstruktion.
Hierbei wird zur Rekonstruktion einer Schicht \(\alpha\) eine möglichst ähnliche Schicht \(\beta\) herangezogen und wird ähnlich der zuvor erwähnten Diagonalisierung mit
\(A'^{[\alpha, \beta]} = \sum^{N}_{k=1} \mu_{k}x^{[\beta]}_{k}x^{[\beta]^{T}}_{k}\)
rekonstruiert.
Damit kann eine beliebige Schicht mit ähnlicher Struktur mittels einer anderen Schicht rekonstruiert werden(Abdolhosseini-Qomi et al., 2020).
Des Weiteren begünstigt eine hohe strutkturelle Ähnlichkeit zwischen zwei Layern die Interlayer Degree Correlation, die ebenso als Evaluationskriterium herangezogen werden kann.
Die Interlayer Degree Correlation ist umso höher, je ähnlicher die Knotengrade netzwerkübergreifend sind, also wenn beispielsweise Knoten a im Layer 1 ein Hub ist und ebenso im Layer 2(Min et al., 2014).
Somit findet die Ähnlichkeit ebenso in anderen Kriterien und mathematischen bzw. algorithmischen Konzepten ihre Anwendung.
4. Anwendung
In diesem Kapitel wird ein Beispieldatensatz anhand der in im dritten Kapitel “Methodik” beschriebenen Kriterien evaluiert und die Ergebnisse der Evaluation werden vorgestellt. Dazu wird als Beispieldatensatz ein Netzwerk aus Interaktionen von Angestellten einer Anwaltskanzlei betrachtet. Die Interaktionen werden in “Advice”, “Friendship” und “Co-work” unterteilt, welche auch die drei Layer des Netzwerks bilden. Insgesamt beinhaltet das Multilayernetzwerk 71 Knoten und 2223 Kanten. Die Daten dafür wurden in einer Studie zu einer US-amerikanischen Anwaltskanzlei erhoben. Dabei sollten die Mitarbeiter der Firma aus einer Liste aller Angestellten einmal diejenigen auswählen, die sie zuletzt für beruflichen Rat aufgesucht hatten, danach die Angestellten, mit denen sie außerberufliche, soziale Interaktionen hatten. Zuletzt sollten sie noch die Angestellten aussuchen, mit denen sie direkt an Fällen zusammengearbeitet hatten (Lazega & others, 2001) (Snijders et al., 2006).
4.1 Anwendung - Knotengrad
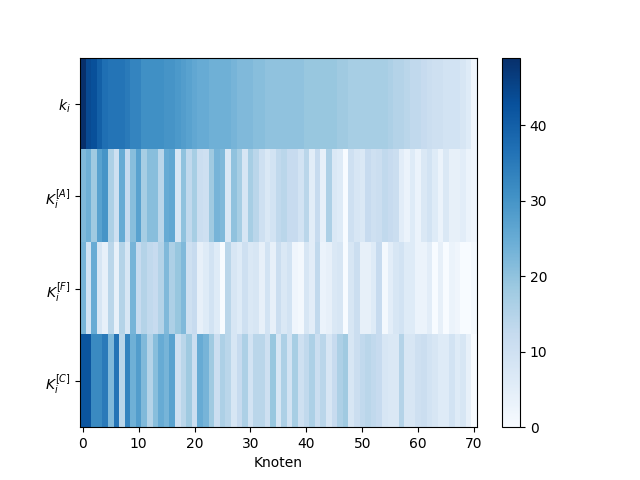
Abbildung 2: Die kumulierten Knotengrade und die Layer-degrees sind für einzelne Knoten spaltenweise abgebildet, wobei die Knoten nach dem kumulierten Knotengrad absteigend sortiert sind.
Es zeigt sich, dass die Layer-degrees untereinander nur wenig korrelieren. Bei Betrachtung der fünf Knoten mit dem höchsten kumulierten Knotengrad fällt auf, dass diese auf der einen Seite Hubs in Layer drei und auf der anderen Seite deutlich isolierter in Layer eins und zwei sind.
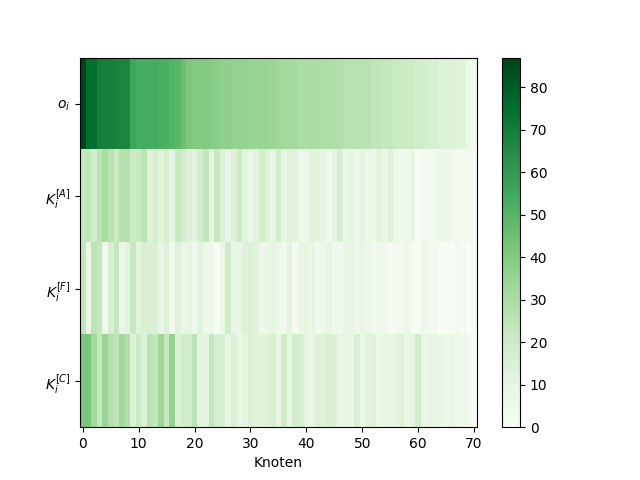
Abbildung 3: Die überlappenden Knotengrade und die Layer-degree sind für einzelne Knoten spaltenweise abgebildet, wobei die Knoten nach dem overlapping degree absteigend sortiert sind.
Ähnlich wie bei Abbildung 2 zeigt sich hier, dass die Layer-degree mit dem overlapping degree nur schwach zusammenhängen.
4.2 Anwendung - correlation coefficient
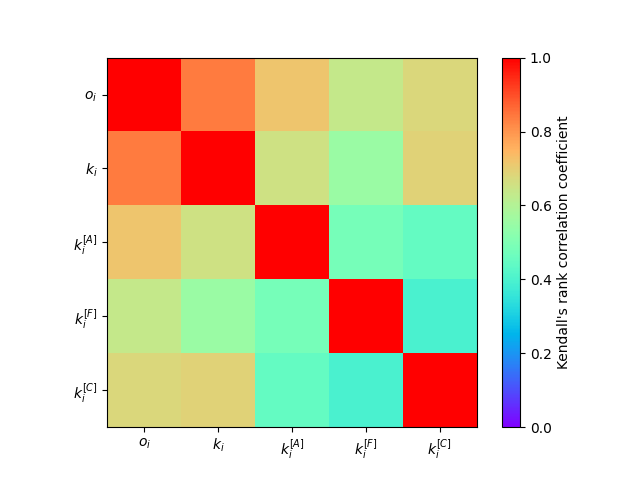
Abbildung 4: Heatmap zur Darstellung des Kendall rank correlation coefficient zwischen den Arten von Knotengraden
Aus Abbildung 4 lässt sich schließen, dass von den drei Layern, der Advice-Layer am stärksten mit dem overlapping degree korreliert, d.h. dass die Rolle der Knoten in dem Advice-Layer bezüglich ihres Knotengrades am Stärksten die Rolle der Knoten im gesamten Netzwerk widerspiegelt. Der Co-working-Layer steht mit dem kumulierten Knotengrad im größten Zusammenhang und ist daher am Repräsentativsten für die Knotengrade im kumulierten Netzwerk. Unter den Kendall rank correlation coefficients der Layer-degrees ist die Korrelation zwischen dem Advice-Layer und dem Friendship-Layer am Größten. Darunter liegt die Korrelation zwischen dem Advice-Layer und dem Co-work-Layer und am kleinsten ist \(\tau\) zwischen dem Friendship- und dem Co-work-Layer. Dies entspricht den Erwartungen, wenn man bedenkt, dass die Anwälte, die vielen anderen Angestellten helfen, auch tendenziell viele Freundschaften bzw. direkten Kollegen haben. Andererseits ist der Zusammenhang zwischen der Anzahl an Freundschaften und der Anzahl an direkten Kollegen nicht klar, weswegen die Korrelation dort am niedrigsten ausfällt.
4.3 Anwendung - participation coefficient
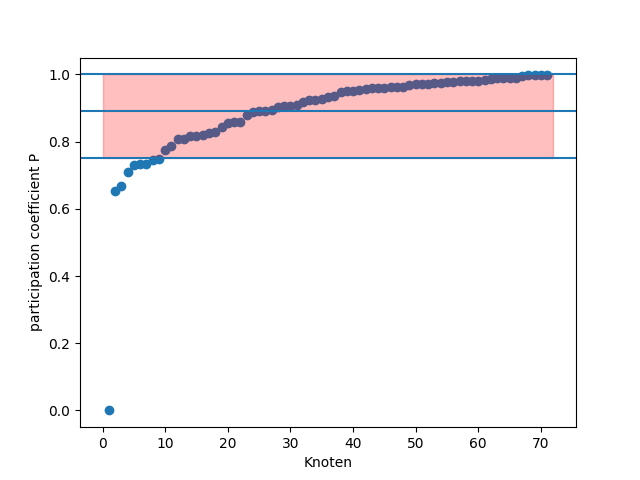
Abbildung 5: Der participation coefficient wird sortiert nach Größe abgebildet. Die rot markierte Fläche beinhaltet alle Knoten, die innerhalb der Standardabweichung um den Durchschnitt liegen.
Der im Durchschnitt hohe participation coefficient von \(P = 0,89\) zeigt, dass die Knotengrade eines Knoten im Durchschnitt über die Layer hinweg ähnlich verteilt sind. Größtenteils ist der participation coefficient sehr homogen, d.h. die Knoten liegen nah beieinander, was sich auch anhand der niedrigen Standardabweichung zeigt. Abgesehen davon sticht Knoten sechs hervor. Von ihm gehen nur in Layer 3 Kanten aus, sodass sein participation coefficient \(P = 0\) beträgt.
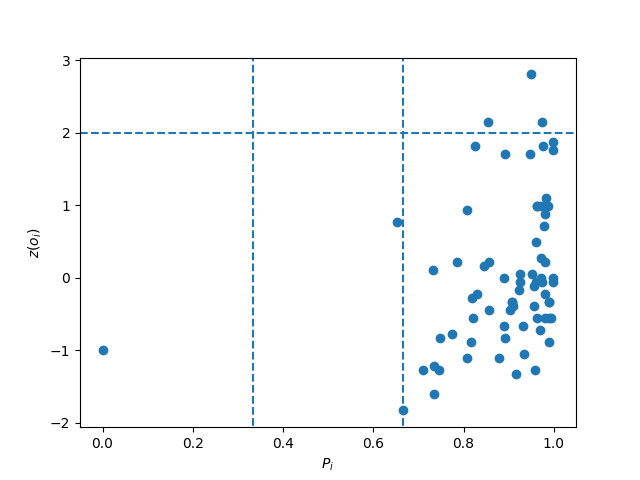
Abbildung 6: Z-score in Abhängigkeit des “participation coefficient”
Aus Abbildung 6 ist zu entnehmen, dass die meisten Knoten in derselben Klasse und zwar in der Klasse der normalen, multiplexen Knoten zu finden sind. Trotzdessen lässt sich erkennen: Knoten mit gleichem oder ähnlichen Z-score, also gleicher bzw. ähnlicher Relevanz auf das gesamte Netzwerk bezogen, übernehmen unterschiedliche Rollen bezüglich ihrer Zentralität über die Layer hinweg. Beispielsweise haben Knoten sechs und neun beide einen ähnlichen Z-score von rund -1,005 und -1,060, unterscheiden sich jedoch bei ihrem “participation coefficient” um ungefähr 0,93. Somit ist Knoten sechs maximal konzentriert und Knoten neun sehr multiplex.
4.4 Anwendung - Ähnlichkeitsbemessung
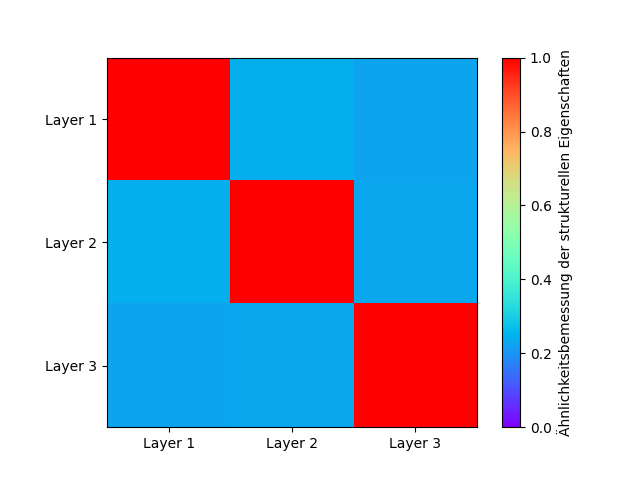
Abbildung 7: Heatmap “Ähnlichkeitsbemessung der strukturellen Eigenschaften”
Die Achsen sind entsprechend beschriftet, sodass man erkennen kann, welcher Layer wie ähnlich zu einem anderen Layer ist. Hierbei ist zu sehen, dass die Diagonale rot ist. Dies bedeutet exakte Gleichheit.
In diesem Fall spiegelt die Diagonale die Ähnlichkeitsverhältnisse eines beliebigen Layer zu sich selbst wieder. Eine Schicht ist zu sich selbst identisch, wie in 3.2.2 bereits beschrieben, daher betragen jene Einträge den Wert 1.
Die Einträge der Heatmap sind im Intervall \([0,2;0,25]\) und je ähnlicher sich zwei Layer sind, desto größer wird der Wert sein.
Abseits der Diagonalen sind kalte Farben vertreten, vor allem blau. Bei genauerem Hinblicken sieht man, dass diese Blautöne allerdings nicht gleich sind, sondern leicht variieren, das heißt, dass es Unterschiede zwischen der Ähnlichkeit der jeweiligen Schichten zueinander gibt.
Am ähnlichsten sind sich Layer 1 und 2 mit einem Wert von ca. \(0,24\) und am unähnlichsten Layer 1 und 3 mit einem Wert von ca. \(0,225\).
Da die Ähnlichkeit hier sich betragsmäßig zwischen einem Fünftel bis einem Viertel befindet, sollte man allerdings nicht schlussfolgern, dass in einem Layer keine Strukturen anderer Layer vorkommen.
Anhand der Werte lässt sich erkennen, dass die Layer eine gewisse strukturelle Ähnlichkeiten zueinander besitzen, auch wenn diese gering ist.
5. Diskussion
Nachdem wir im vorangegangen Kapitel die Ergebnisse unserer Anwendung präsentiert haben, möchten wir diese hier kurz diskutieren. Die Analyse des participation coefficient ergab, dass die Verteilung der ausgehenden Kanten über die Layer bei Betrachtung einzelner Knoten sehr homogen, also gleichverteilt, ist. Dies wurde durch den hohen Durchschnitt von 0,89 und die niedrige Standardabweichung von 0,12 gestützt. Nach der Einteilung der Knoten in die sechs Klassen befand sich die Mehrheit der Knoten in der Klasse der gewöhnlichen, multiplexen Knoten, was zeigt, dass ein Großteil der Knoten eine ähnliche Zentralität in den Layern besitzt. Drei Knoten sind Hubs und bei zwei von ihnen liegt der participation coefficient bei über 0,9. Das zeigt, dass die wichtigsten Knoten im Netzwerk auch zu den Knoten mit einer besonders homogenen Kantenverteilung gehören. Bei Betrachtung der Korrelation zwischen den Layern mittels des Kendall coefficient kommen wir zu anderen Ergebnissen. Die Layer zeigen sich als eher schwach zusammenhängend mit Kendall coefficients im Intervall von 0,3 bis 0,45. Dabei hängen der Advice-Layer und der Friendship-Layer am stärksten zusammen und der Friendship- und Co-work-Layer am schwächsten. Das Ergebnis der am stärksten korrelierenden Layer deckt sich mit dem der Ähnlichkeitsbemessung. Dort ist ebenfalls die Korrelation zwischen Advice- und Friendship-Layer am Größten. Intuitiv ist dieses Ergebnis nachvollziehbar, da Angestellte, die vielen anderen Angestellten helfen, was in dem Advice-Layer dargestellt wird, auch viele Freunde unter den anderen Angestellten haben. Jedoch arbeiten Angestellte mit vielen Freunden nicht unbedingt mit einer hohen Anzahl an direkten Kollegen zusammen, was die vergleichsweise niedrigere Korrelation zwischen dem Friendship- und dem Co-work-Layer erklären würde. Diese These deckt sich allerdings nicht mit den Ergebnissen der Ähnlichkeitsbemessung. Denn dort ist die Korrelation zwischen Advice- und Co-work-Layer am schwächsten. Zudem muss angemerkt werden, dass die Unterschiede zwischen den Korrelationen bei beiden Methoden gering waren. Insgesamt ist die Korrelation zwischen den Layer nach dem Kendall coefficient tendenziell schwach zusammenhängend und nach der Ähnlichkeitsbemessung deutlicher schwach korrelierend, sodass man anhand dieser Messung die Layer als negativ-korrelierend bezeichnen könnte.
6. Zusammenfassung
In unserem Paper haben wir zwei Evaluationskriterien, die Zentralität und die “Ähnlichkeit auf einem Beispielgraph analysiert. Dabei wurde zunächst die Methodik der Knotengradeigenschaften, des correlation coefficient und des participation coefficient erläutert. Zudem wurde die Ähnlichkeit vorgestellt. Daraufhin wurden die vorgestellten Konzepte auf ein Beispielnetzwerk angewendet und die Ergebnisse dessen präsentiert. Dabei hat sich die Kantenverteilung einzelner Knoten über die Layer hinweg als homogen herausgestellt. Die Auswertung der Korrelation der Layer mit dem kendall coefficient und der Ähnlichkeitsbemessung ergab, dass die Layer negativ-korrelierend zueinander sind.
Mit unserer Arbeit trugen wir zur Erforschung der Analyse von Multilayernetzwerken bei, indem wir die Methodik zur Bemessung der Ähnlichkeit und Zentralität vorgestellt und exemplarisch auf ein Beispielnetzwerk angewendet haben. Zentralität und Ähnlichkeit sind bekannte Kriterien mit hoher Nützlichkeit. In der Zukunft wird möglicherweise ihr Potenzial sowie die Notwendigkeit zur Erforschung dieser Kriterien mit den wachsenden Anwendungsmöglichkeiten von Multilayernetzwerken steigen.
7. Referenzen
- van den Heuvel, M. P., & Sporns, O. (2013). Network hubs in the human brain. Trends in Cognitive Sciences, 17(12), 683–696.
- Battiston, F., Nicosia, V., & Latora, V. (2014). Structural measures for multiplex networks. Physical Review E, 89(3), 032804.
- Boccaletti, S., Bianconi, G., Criado, R., Del Genio, C. I., Gómez-Gardenes, J., Romance, M., Sendina-Nadal, I., Wang, Z., & Zanin, M. (2014). The structure and dynamics of multilayer networks. Physics Reports, 544(1), 1–122.
- Abdolhosseini-Qomi, A. M., Jafari, S. H., Taghizadeh, A., Yazdani, N., Asadpour, M., & Rahgozar, M. (2020). Link prediction in real-world multiplex networks via layer reconstruction method. Royal Society Open Science, 7(7), 191928.
- Min, B., Do Yi, S., Lee, K.-M., & Goh, K.-I. (2014). Network robustness of multiplex networks with interlayer degree correlations. Physical Review E, 89(4), 042811.
- Wang, L., Li, S., Wang, W., Yang, W., & Wang, H. (2021). A bank liquidity multilayer network based on media emotion. The European Physical Journal B, 94(2), 1–23.
- Lü, L., Pan, L., Zhou, T., Zhang, Y.-C., & Stanley, H. E. (2015). Toward link predictability of complex networks. Proceedings of the National Academy of Sciences, 112(8), 2325–2330.
- Lazega, E., & others. (2001). The collegial phenomenon: The social mechanisms of cooperation among peers in a corporate law partnership. Oxford University Press on Demand.
- Snijders, T. A. B., Pattison, P. E., Robins, G. L., & Handcock, M. S. (2006). New specifications for exponential random graph models. Sociological Methodology, 36(1), 99–153.