Flow Based Algorithms
| Esther R. | Joshua Martius |
|---|---|
| RWTH Aachen University | RWTH Aachen University |
| […]@rwth-aachen.de | joshua.martius@rwth-aachen.de |
Abstract
Inn der Forschung, der freien Wirtschaft und der Politik werden jene (Meta-) Daten, die wir aus sozialen Netzwerken generieren können, immer interessanter und dementsprechend auch die Algorithmen, die diese aus den sozialen Netzwerken extrahieren. Und obwohl eben diese immer mehr an Wichtigkeit gewinnen, gibt es kaum deutsche Quellen mit deren Hilfe man sich darüber informieren kann. In diesem Kapitel des Online-Buches werden die wichtigsten Informationen rund um Flow-based-Alogrithms (Fluss-basierte-Algorithmen) (FBA) zusammengefasst. Dazu sollen verschiedene Vertreter ihrer Art, wie zum Beispiel RelaxMap, InfoMap und OCDID, untereinander verglichen werden, zudem stellen wir einen selbstgeschriebenen FBA zur Veranschaulichung vor. Als Quelle unserer Untersuchungen dienen die Ergebnisse verschiedener internationaler Forschungsteams, welche sich intensiv mit der Implementierung von FBAs beschäftigt haben. Ziel der Arbeit ist eine Grundlage deutscher Literatur zu bilden.
Einleitung
Die moderne Wissenschaft der Netzwerke hat unser Verständnis komplexer Systeme erheblich verbessert. Community Detection ist ein zunehmend beliebter Ansatz, um wichtige Strukturen in großen Netzwerken zu finden, zu gruppieren und auszuwerten. Eine Art dies umzusetzen sind Fluss basierte Algorithmen (FBA). Diese basieren eher auf Kommunikationsmustern des Netzwerks als auf strukturellen Eigenschaften, um Communitys zu bestimmen. Mittlerweile wurden schon viele Ansätze zur Analyse von Communitys in Netzwerken entwickelt (siehe verwandte Arbeiten), jedoch gestaltet sich die Recherche schwer, da es kaum deutsche Texte zu den verschiedenen Community Detection Algorithmen gibt. Deshalb stellen wir hier vor, was FBA’s sind und wofür sie eingesetzt werden, indem wir andere wissenschaftliche Arbeiten zusammenfassen und einen Beispielalgorithmus präsentieren.
Anlass unserer Arbeit ist das Fehlen deutschsprachiger Literatur zum Thema Flow Based Algorithms. Um zukünftigen Interessenten das langwierige Vergleichen englischsprachiger Arbeiten zu ersparen, haben wir innerhalb unserer Ausarbeitung unterschiedliche Algorithmen untersucht und die Ergebnisse hier komfortabel im Deutschen zusammengetragen.
Dabei gliedert sich das Kapitel wie folgt:
Zuerst zeigen wir auf was ein FBA ist, wie er funktioniert und präsentieren eine Beispielimplementation, welche an Infomap angelehnt ist. Weiterführend soll überprüft werden, inwiefern sich die Bewertung des Einflusses einzelner Individuen auf die Community mithilfe von FBAs realisisieren lässt. Wichtige Kriterien sind unter anderem wie sich Korrektheit, Laufzeit, aber auch Genauigkeit und die Anwendbarkeit beziehungsweise Flexibilität bei verschiedenen Formen von sozialen Netzwerken unterscheiden lässt.
Verwandte Arbeiten
Zur Vorbereitung auf die Ausarbeitung dieses Papers haben wir uns mit einigen Wissenschaftlichen Arbeiten zu ähnlichen Themen beschäftigt. Unser Beispielalgorithmus ist an den Infomap (missing reference) Algorithmus angelehnt, welcher erstmals 2015 als Methode, die auf einer Komprimierung von Netzwerkflüssen basiert, vorkam. In der Arbeit “Scalable Flow-Based community Detection for Large-Scale Network Analysis” (Bae et al., 2013) von Mitgliedern der University of Washington wird ein verbesserter Algorithmus namens RelaxMap vorgestellt, der parallel statt seriell arbeitet. “Overlapping Community Detection Based on Information Dynamics” (Sun et al., 2018) ist eine Studie in der ein neues Modell namens OCDID (Overlapping Community Detection basierend auf Information Dynamics) zur besseren Analyse von überlappenden Communities vorgeschlagen wird.
Angewandte Methodik
Als Input des Pseudocodes wird die folgende Eingabe erwartet: \(G = (V, E)\) (Netzwerk) als 2-Dimensionales Array mit 2- bzw. 3-Tupeln. \(G\) sei ein Graph, bestehend aus einer Menge an Knoten \(V\) (Vertices) und einer Menge Kanten \(E\) (Edges). Das Tupel sei genau so strukturiert: (Startknoten, Zielknoten, [Gewicht]). Das Gewicht ist hier bei optional, um auch die Möglichkeit zu bieten, ungewichtete Netzwerke beziehungsweise Graphen zu analysieren. Die Bedeutung des Gewichtes wird hierbei durch das zu untersuchende Netzwerk definiert. Das allgemeine Gewicht ist eine Zahl die exakt einer Kante zugeordnet ist.
Als Beispielalgorithmus haben wir uns den InfoMap Algorithmus vorgenommen. Der Pseudocode zur Implementation ist in Abbildung 1 zu finden. Dieser Algorithmus dient der Community Detection, welcher versucht, die Map equation zu minimieren. Er optimiert dafür die Gleichung und bietet so ein Tool für schnelle Aufteilung eines Netzwerks in verschiedene Gruppen.
(Abbildung 1)
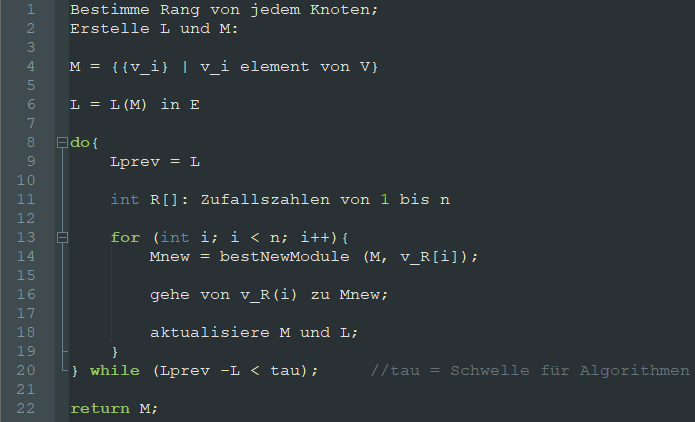
Die Map Equation bildet die Grundlage für den InfoMap Algorithmus. Ihre Funktion wird im folgenden Punkt Funktionsweise erklärt.
\(L(M)\) ist die Ausgabe der Map Equation. Es gibt die kürzeste Beschreibungslänge für den gegebenen Graphen, zerteilt in \(M\) Module.
Tau ist der Schwellwert, der wieder gibt bis zu welchem Optimierungsgrad der Algorithmus die Communitydetection versuchen soll. Er dient dazu eine Terminierung sicherzustellen.
Funktionsweise
Als Beispiel nehmen wir uns, wie schon in Abbildung 1, den InfoMap Algorithmus vor. Die grundlegende Funktion ist dem Pseudocode zu entnehmen, wird aber in den folgenden Zeilen ausführlicher erklärt.
Der InfoMap Algorithmus basiert auf der sogenannten Map equation. Diese existiert in verschiedenen Formen, wir haben uns für die aus Abbildung 2 entschieden. Die Gleichung überzeugt durch verhältnismäßig einfache Implementierung und solide Genauigkeit.
(Abbildung 2)
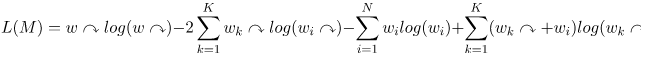
Das Ziel des Algorithmus ist die Minimierung der map equation. Daraus resultiert eine möglichst genaue Zerteilung eines Graphen in Communities. Die Schritte des Vorgehens sehen (anhand des Pseudocodes) wie folgt aus:
Input:
- Graph G, bestehend aus Menge der Knoten V und Kanten E.
- Quaility improvement treshhold (QIT) in Form einer Dezimalzahl.
Ablauf:
- Nehme ein beliebiges Element x aus beliebiger Gruppe A.
- Finde eine Gruppe B für die gilt: B ist erreichbar von A. (Verbunden über ein Minimum an Kanten)
- Übertrage x in B
- Überprüfe: Ist L(M) nun echt kleiner als zuvor?
- Wenn ja: Behalte x in B für den nächsten Vorgang
- Wenn nein: Übertrage x zurück in A, fahre mit nächstem Element fort
- Führe Schritte 1-4 einmal für alle Elemente von M aus.
- Führe Schritte 1-5 solange aus, bis L(M) dem gewünschten Schwellwert (QIT) entspricht oder kleiner ist.
Die in Abbildung 1 erwähnte Methode bestNewModule() ist hierbei für Schritt 2 verantwortlich. Diese Methode findet die nächstmögliche Gruppe. Module sei hierbei ein Synonym für eine Gruppe.
Effizienz der Anwendung von FBAs auf soziale Netzwerke
Der Infomap-Algorithmus optimiert eine neuartige Zielfunktion, die als Map equation bezeichnet wird, und es wurde gezeigt, dass sie vor allem in der Genauigkeit andere Ansätze übertrifft (siehe (missing reference) für Benchmarks). Infomap und seine Varianten sind jedoch sequentiell, was ihre Verwendung für große Diagramme einschränkt, das ist sehr schlecht, da die meisten realen Netzwerke sehr groß sind.
Vergleich zwischen verschiedenen Implementationen
InfoMap ist jedoch nicht der einzige FBA. Verschiedene Entwickler arbeiten an verbesserten und spezialisierten Implementationen von Flow based Algorithmen.
Algorithmen wie RelaxMap bieten dagegen Parallelisierung und Priorisierung an. Parallelisierung, damit die Map Equation für viel größere Diagramme optimiert werden kann. Priorisierung wird benötigt, damit die wichtigsten Arbeiten zuerst ausgeführt werden, Iterationen weniger Zeit in Anspruch nehmen und der Algorithmus schneller terminiert. Die Bewertung aus (Bae et al., 2013) zeigt, dass beide Techniken effektiv sind: RelaxMap erreicht eine parallele Effizienz von 70 Prozent auf acht Kernen. Während die Priorisierung die Algorithmusleistung in Abhängigkeit von den Grapheneigenschaften um durchschnittlich weitere 20 bis 50 Prozent verbessert. Darüber hinaus terminieren beide Implementationen nach einer ähnlichen Anzahl von Iterationen.
Mit überlappenden Communities haben die meisten Algorithmen, beim aktuellen Stand der Technik, noch Schwierigkeiten (z.B. auf Grund der Parametereinstellungen), weshalb OCDID(Sun et al., 2018) (Overlapping Community Detection) basierend auf Information Dynamics, entwickelt wurde. Diese werden in den meisten Fällen anderen repräsentativen Algorithmen (z.B. SLPA) hinsichtlich der Qualität der Erkennung überlappender Communitys überlegen sein.
Es ist also unmöglich den einen besten Algorithmus für Community Detection zu bestimmen. Je nach Größe und Art des Netzwerkes unterscheiden sich auch die Qualitäten der Algorithmen.
Zusammenfassung und Ausblick
In dieser Ausarbeitung haben wir Fluss-basierte Algorithmen zur Entdeckung von Communitys in sozialen Netzwerken vorgestellt. Insbesondere sind wir auf den, Infomap Algorithmus eingegangen, welcher mittels Minimierung der map equation die einzelnen Communities herausfiltert.
In Zukunft wird Communitiy Detection auch weiterhin ein wichtiges Thema bleiben, eventuell sogar durch die Masse an Informationen in Netzwerken noch an Relevanz gewinnen. Vor allem fehlen der Forschung noch Algorithmen die besser mit sehr großen und überlappenden Netzwerken zurechtkommen. Aus diesen Gründen sind in diesem Gebiet noch viele Studien und weitere wissenschaftliche Ausarbeitungen zu erwarten. Das Fachgebiet der sogenannten Data Science wird sich immer weiter vergrößern und Data Analysts immer gefragter.
Referenzen
Zur Vorbereitung auf die Ausarbeitung dieses Papers haben wir uns mit folgenden Arbeiten zu ähnlichen Themen beschäftigt:
- Bae, S.-H., Halperin, D., West, J., Rosvall, M., & Howe, B. (2013). Scalable flow-based community detection for large-scale network analysis. 2013 IEEE 13th International Conference on Data Mining Workshops, 303–310.
- Sun, Z., Wang, B., Sheng, J., Yu, Z., & Shao, J. (2018). Overlapping community detection based on information dynamics. IEEE Access, 6, 70919–70934.