Datensätze für soziale Netzwerke
| Fidelius Lula | Fubang Wu | ||
|---|---|---|---|
| RWTH Aachen University | RWTH Aachen University | ||
| fidelius.lula@rwth-aachen.de | fubang.wu@rwth-aachen.de |
Inhaltsverzeichnis
1. Abstract
Wenn es etwas gibt was die heutige Gesellschaft identifiziert, dann sind das soziale Netzwerke. Fast jeder einzelne ist Teil eines solchen Netzwerks und interagiert mit anderen Menschen überall auf der Welt. Innerhalb eines solchen sozialen Netzwerkes lassen sich stets Gemeinschaften, sogenannte Communities finden, in denen sich Benutzer, dargestellt als Knoten, mit gleichen Freunden, Interessen oder anderen Ähnlichkeiten miteinander, befinden. Diese Communities sind manchmal einfach und manchmal nicht so trivial zu erkennen. Visualisiert werden diese Netzwerke in Graphen, wobei Knoten Personen und Kanten die Interaktion zwischen Personen repräsentieren. Um aussagekräftige Thesen über die Gesellschaft aufzustellen ist es also sinnvoll, Datensätze sozialer Netzwerke zu betrachten. Es gibt mehrere Publikationen, die sich mit dem Thema befassen. Im Folgenden wollen wir aber einen andere Art von Analyse durchführen indem wir Datensätze aus verschiedenen sozialen Netzwerken betrachten und dabei analysieren, einerseits wie gut sich die Algorithmen auf die Datensätze verhalten. Insbesondere soll aber der Fokus auf dem Unterschied dieser Datensätze zwischen verschiedenen Netzwerken legen. Dieser Vergleich basiert hauptsächlich auf die Ergebnisse verschiedener OCD-Algorithmen die wir auf solchen Datensätzen mit Hilfe des WebOCD-Clients laufen lassen.
2. Einleitung
Soziale Netzwerke im Internet ermöglichen den Benutzern Unmengen an Informationen und Daten zu verfolgen, die von den Freunden oder auch andere Benutzer hochgeladen wurden. Als Benutzer eines sozialen Netzwerkes gibt man alles mögliche an Daten an: Wie heiße ich? Wie alt bin ich? Wo bin ich zur Schule gegangen? Was war meine erste Arbeitsstelle? Was mag ich? Was mag ich nicht? Mit wem bin ich befreundet? Die Informationen, die aus diesen enormen Datenmengen gewonnen werden können für unterschiedliche Zwecke gebraucht wie beispielsweise für die Schaltung einer an den Nutzer angepasste Werbung.
Die Daten aus solchen Netzwerken sind äußerst detailliert, man findet neben den einzelnd herumschwimmenden Daten auch Zusammenhänge oder auch “Communities” innerhalb eines Netzwerkes. Einzelne Knoten können über Eigenschaften besitzen, welches sie mit anderen Knoten in eine Beziehung setzt. Es geht sogar noch weiter: Aus welcher Dimension ist solch eine “Community” entstanden? Existiert noch eine andere “Community” innerhalb der bereits vorhandenen “Community”? Besteht eine hierarchische Struktur? Aus analytischer Sicht ist die riesige Menge an Daten sowohl Segen als auch Fluch, denn mit Mengen dieser Größe effektiv zu arbeiten ist eine Herausforderung.
Aktuell besteht großes Interesse an der Analyse und Deutung von solchen Daten, weswegen viel Arbeit darein investiert wird. Gerade in sozialen Netzwerken, wo die Informationen sowohl für große Unternehmen und auch Wissenschaftler lukrativ sind. Ist es von Bedeutung, ein Format für die Datensätze zu finden. Neben dem Datenformat ist es auch von großen Nutzen zu wissen, welche Algortihmen für solchen Datenformat geeignet ist. Welche Algorithmen sind nun am effizientesten und am meisten geeignet für soziale Netzwerke. Das beantworten dieser Frage kann in der praktischen Arbeit viel Zeit und auch Geld sparen.
Zunächst, sollen die von uns benutzte öffentlich zugängliche Datensätze und ihren Zusammenhang zu den sozialen Netzwerken dargestellt werdern. Die dargestellten Algorithmen werden auch erklärt und es wird hervorgehoben, aus welchem Grund sich diese Algorithmen aufgrund ihrer Eigenschaften für die Untersuchungen anbieten.
Dann werden wir die von uns ausgewählten vier Algorithmen auf öffentlich zugängliche Datensätze von sozialen Netzwerken vergleichen. Zuerst soll die Laufzeit verglichen werden, die Auskunft über die Effizienz geben soll. Danach werden die, über die Algorithmen auffindbaren Communities verglichen, um die Qualität der Daten im Hinblick auf den jeweiligen Datensatz offenzulegen. Dafür verwenden wir den WebOCD-Client (https://webocd.dbis.rwth-aachen.de/OCDWebClient) von der RWTH als Werkzeug, indem wir die Datensätze in entsprechenden Format hochladen um sie anschließend mit von uns ausgesuchten Algorithmen zu vergleichen.
Im Laufe der Analyse sollen auf Basis der Ergebnisse Tabellen entwickelt werden, die erste Deutungen erlauben.
Am Ende der Arbeit wird auf eine Antwort aus den Beobachtungen hingearbeitet. Diese wird als endgültiges Produkt dieser Arbeit vorgestellt.
3. Verwandte Arbeiten
Sowohl Gruppenfindungsalgorithmen als auch die Modellierung von Datensätze sind zentralen Themen in der Datenanalyse. Algorithmen für Gruppenfindung in sozialen Netzwerken wurde schon in der Arbeit von (Nerurkar et al., 2019) behandelt. Welche acht Algorithmen auf ihre Effizienz und Eignung kritisch verglichen hat. Wir werden in unserer Arbeit vier weitere Algorithmen analysieren und die Arbeit von (Nerurkar et al., 2019) erweitern und mehr Perspektive ins Thema Gruppenfindungsalgorithmen bringen. Neben den Algorithmen ist auch die Modellierung der Datensätze wichtig, die (McAuley & Leskovec, 2012) in ihrer Arbeit analysiert haben.
4. Methodik
Netzwerke werden häufig durch Graphen dargestellt. Graphen sind mathematische Strukturen, die aus sogenannte Knoten und Kanten bestehen. Als Notation verwendet mann für einen Graphen \(G\) mit \(V\) Knoten und \(E\) Kanten: \(G = (V, E)\). Diese Parameter haben je nach Anwednungsfeld verschiedene Bedeutungen. Für die Analyse sozialer Netzwerke symbolisieren die Knoten, die teilnehmenden Individuuen und eine Kante zwischen 2 Knoten stellt eine Verbindung zwischen diesen Individuuen dar. Diese Verbindung kann ungewichtet sein oder gewichtet sein. Im falle eines ungewicheteten Graphen, hat eine Kante lediglich eine binäre Bedeutung, nämlich ob eine Verbindung besteht oder nicht. Im Falle eines gewichteten Graphen, gehört zu dem Graphen auch eine Abbildung, die die Kanten in numerische Werte abbildet. Zusammen mit dieser Abbildung wird der Graph folglich beschrieben: \((G, f) = (V, E), f: E \rightarrow \mathbb{R}\). In sozialen realitätsnahen Netzwerken kommen sowohl gewichtete als auch ungewichtete Graphen, bzw. Netzwerke vor. In diesem Paper werden wir versuchen, mit Hilfe speziell entwickelter Algorithmen zur Analyse von sozialen Netzwerken, die ausgewählten Datensätze zu untersuchen. Die 3 Overlapping Communities Algorithms die wir bei unserer Arbeit näher betrachten und auch benutzen sind: DMID, SPLA und der CliZZ-Algorithmus, die auch in der uns verfügbar-gestellten WebOCD-Client implementiert sind.
DMID-Algorithmus
Der DMID-Algorithmus(Disassortative Degree Mixing and Information Diffusion) ist ein Algorithmus für gewichtete und ungewischtete Graphen, der speziell für soziale Netzwerke entickelt wurde, jedoch lässt er sich auch sehr gut in technischen Netzwerken anwenden. Durch seine relativ gute Laufzeit, auch auf großen und realitätsnahen Netzwerken ist er Konkurrenzfähig in Präzision und bietet auch einen sehr hohen Modularitätswert. Der Modularitätswert ist ein Maß für die Struktur von Netzen oder Graphen, das die Stärke der Unterteilung eines Netzes in Module (Gruppen, Cluster, Communities) misst. Netzwerke mit hoher Modularität haben dichte Verbindungen zwischen den Knoten innerhalb von communities, aber spärliche Verbindungen zwischen Knoten die Teil verschiedener Communities sind.
Dieser Algorithmus basiert auf das sogenannte “Disassortative mixing”, was die Tendenz eines Knotens, hauptsächlich mit Knoten in Verbindung zu stehen, die einen Rang/Grad einer anderen Größenordnung besitzen, ausdrückt. Ein Knoten mit einem hohen Rang/Grad kommuniziert also vorwiegend mit niedrigrangigen/-gradigen Knoten und umgekehrt. Ein einzelner Knoten ist folglich genau dann disassortativ, wenn sein Grad stark vom Grad der meisten Nachbarknoten abweicht. Diese Art von Beziehung ist nicht zufällig gewählt, sondern finden sich häufig in vielen Communitys in sozialen Netzwerken wieder und trifft somit auch auf die Beziehung der Anführer und ihrer Nachbarknoten zu.
SLPA-Algorithmus
Der SLPA-Algorithmus(Speaker Listener Propagation Algorithm) ist ein effizienter Algorithmus mit Parameter der nur auf ungewichtete Graphen läuft. SLPA findet nicht nur Overlaping Communities, sondern sogar einzelne Overlaping Knoten, die sogenannten Schnittstellen dieser Communities. Seine Laufzeit ist fast liner, leider aber nicht sehr stabil da der Algorithmus keine eindeutige Lösung zurückgibt. Technisch gesehen basiert der Algorithmus, wie der Name schon sagt, auf dem “Label-Austausch”, zwischen den Speaker-Knoten und den Listener-Knoten. Diese Herangehensweise ist so gewählt damit es gezielt das menschliche Sozialverhalten imitieren kann. Folglich ist auch dieser Algorithmus spezialisiert auf soziale Netzwerke.
CliZZ-Algorithmus
Der CliZZ-Algorithmus gehört auch zu den Algorithmen die Communities insbesondere in sozialen Netzwerken erkennen. Er überzeugt vor allem durch ein hohes Maß and Genauigkeit und Effizienz um diese Communities zu erkennen. Eine besondere Eigenschaft von CliZZ ist seine Fähigkeit um nur mit lokalen Informationen zu arbeiten und somit nicht den Gesamtzustand des Netzwerks kennen zu müssen. Technisch gesehen, bassiert dieser Algorithmus auf Zugehörigkeitsvektoren für Knoten, daher verlangt auch dieser Algorithmus Parameter. Er geht dabei so vor, indem er die Anzahl der Leader im Netzwerk bestimmt, die gleichbedeutend sind mit der tatsächlichen Anzahl an Communities. In Sachen Ergebnissqualität und Laufzeit, liefert CliZZ, auch auf großen Netzwerken, relativ gute Werte.
MONC-Algorithmus
Der MONC-Algorithmus(Merging of overlapping natural communities) ist ein lokaler, parameterfreier Algorithmus der nur auf gewichtete Graphen läuft. Diesen Algorithmus werden wir speziell für das Bitcoin-Datensatz benutzen, da es als einziger Datensatz, gewichtet ist. MONC geht typischerweise analytisch vor, leider liefert er aber keine guten Ergebnisse. Vor allem bei kleinen Netzwerken findet MONC nicht alle Communities bei einer moderaten Laufzeit. Bei großen Netzerken liefert er überdurchnittlichen Ergebnisse bei einer vergleichsweise durchschnittlichen Laufzeit. Auch MONC ist spezialisiert auf soziale Netzwerke, kann aber auch auf Datensätzen aus anderen Bereichen laufen.
5. Experimente
Auswahl der Datensätze
Die Datensätze, die in dieser Arbeit untersucht und verglichen werden haben wir aus den Webseiten https://www.networkrepository.com/soc.php und http://snap.stanford.edu/data/#socnets heruntergeladen. Verschiedene Datensätze werden in verschiedene Formate gespeichert, daher war es nötig gegebenenfalls vor dem Importieren, die Datensätze anzupassen.
Alle Datensätze wurden in eine Edge-List im .txt Format konvertiert und konnten somit auf dem WebOCD-Client hochgeladen und analysiert werden. Bei der Suche und Auswahl der Datensätze haben wir auch auf die entsprechende Größe dieser Datensätze geachtet. Bedauerlicherweise ist der WebOCD-Client sehr anfällig auf große Graphen, mit gegebenenfalls sehr lange Wartezeiten. Daher haben alle ausgewählten Datensätze nicht mehr als 100.000 Kanten insgesamt.
Ein anderer Punkt wo wir uns basiert haben ist natürlich die Ausdruckstärke der Datensätze. Wir haben uns gezielt bemüht aus 3 unterschiedlichen sozialen Netzwerken, Datensätze zu sammeln um somit die Besonderheiten jedes “Genres” zum Ausdruck zu bringen. Ein kurzer, genereller Überblick über alle gesammelten Datensätzen findet sich in folgender Tabelle:
Datensätze - Erklärung
Soziale Kontakte von Facebook (McAuley & Leskovec, 2012)
Wenn es um soziale Netzwerke geht, dann denkt mann automatisch an Facebook. Weil Facebook so weit verbreitet ist, haben wir uns für dieses Datensatz entschieden, in der Hoffnung, dass es so ausdrucksvoll wie möglich für soziale Netzwerke mit sozialen Kontakten ist. Dieser Datensatz ist also ein großes Netzwerk von Kontakten. Das heißt also, falls eine Kante \(E\) zwischen 2 Knoten \(V_1\) und \(V_2\) existiert, so hatten diese Knoten miteinander Kontakt verknüpft, im Rahmen von Facebook. Aus Datenschutz Gründen, wurden alle diese Knoten anonymisiert und jedes eine Zahl zugewiesen.
Facebook-Social Gesamtüberblick

Web of Trust von Bitcoin-Alpha (Kumar, Srijan and Spezzano, Francesca and Subrahmanian, VS and Faloutsos, Christos, n.d.)
Da Kryptowährungen immer häufiger ins Bild rücken, haben wir uns für dieses Datensatz entschieden, um zu verstehen wie eine Analyse von einem solchen Netzwerk uns in der Zukunft behilflich sein wird. Da es in allen Bitcoin Transaktionen, vollständige Anonymität bewahrt wird, ist es nützlich ein System zu schaffen um “böse” Nutzer zu markieren. So funktioniert auch Bitcoin-Alpha, wo jeder Nutzer, jedem Nutzer eine Bewertung hinterlassen kann, sei diese negativ oder positiv. Das ist auch der einzige gewichtete Graph in unserem Paper. Jede Kante steht dafür ob es eine Bewertung gegeben hat und der Wert dieser Bewertung ist auch das Gewicht der Kante.
Bitcoin-Alpha Gesamtüberblick

Wiki-votes von Wikipedia (Ryan A. Rossi and Nesreen K. Ahmed, n.d.)
Wikipedia ist eine freie Enzyklopädie, die von Freiwilligen auf der ganzen Welt gemeinschaftlich erstellt wird. Ein kleiner Teil der Wikipedia-Beitragenden sind Administratoren, d. h. Benutzer mit Zugang zu zusätzlichen technischen Funktionen, die bei der Wartung helfen. Damit ein Benutzer Administrator werden kann, wird ein Antrag auf Administratorschaft gestellt, und die Wikipedia-Gemeinschaft entscheidet durch eine öffentliche Diskussion oder eine Abstimmung, wer zum Administrator befördert wird.
Das Netzwerk enthält alle Wikipedia-Abstimmungsdaten seit der Gründung von Wikipedia bis Januar 2008. Die Knoten im Netzwerk stellen Wikipedia-Nutzer dar und eine gerichtete Kante von Knoten \(i\) zu Knoten \(j\) bedeutet, dass Nutzer \(i\) über Nutzer \(j\) abgestimmt hat.
Wikipedia-Votings Gesamtüberblick
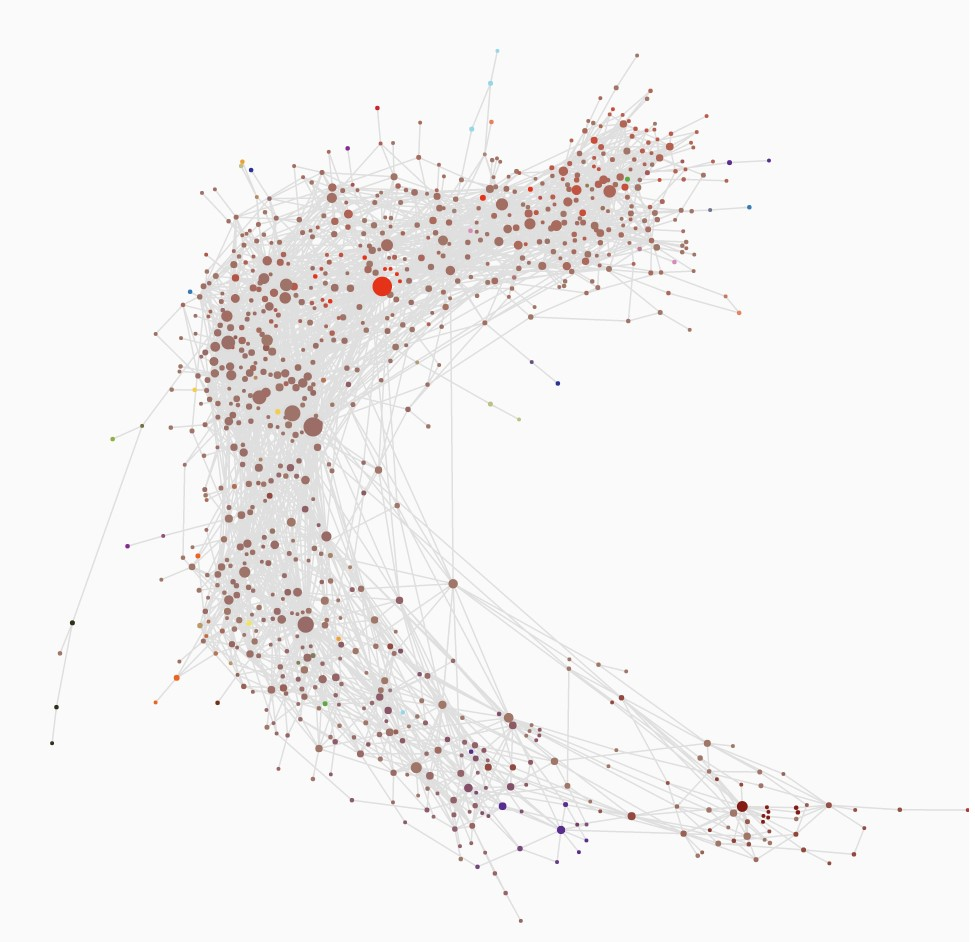
Tv-Shows von Facebook (Ryan A. Rossi and Nesreen K. Ahmed, n.d.)
Facebook ist ein vielseitiges sozialen Netzwerk, wo nicht nur direkte soziale Kontakte verknüpft werden, sondern auch viele Communities auf gemeinsame Präferenzen gegründet werden. Dabei handelt es sich bei diesem Datensatz. Es ist eine Ansammlung von gegenseitig gelikten Facebook-Seiten von Tv und Unterhaltungs-Shows. Knoten repräsentieren die einzelnen Seiten und falls eine Kante zwsichen Knoten \(i\) und Knoten \(j\) besteht, so bedeutet das, dass es gegenseitige Likes zwischen \(i\) und \(j\) gibt.
Facebook-TvShows Gesamtüberblick

Algorithmen auf Datensätze laufen lassen
Mit Hilfe des WebOCD-Clients, haben wir die oben-beschriebenen Algorithmen auf die Datensätze laufen gelassen und die Resultate tabellarisch dargestellt. Außerdem ist für jedes Algorithmus auch die zugehörige Visualisierung dargestellt.
Facebook-Social
Facebook-Social CliZZ Ergebnis

CliZZ
Facebook-Social DMID Ergebnis

DMID
Facebook-Social SLPA Ergebnis

SLPA
Wikipedia-Voting
Wikipedia-Voting DMID Ergebnis
Wikipedia-Voting SLPA Ergebnis
Wikipedia-Voting CliZZ Ergebnis
Bitcoin-Alpha
Aufgrund der zu hohen Überlastung von WEBOCD bei diesem Netzwerk, war es leider unmöglich Visualisierungen zu erhalten.
Facebook Tv-Shows
Facebook-TvShows CliZZ Ergebnis

CliZZ
Facebook-TvShows DMID Ergebnis

DMID
Facebook-TvShows SLPA Ergebnis

SLPA
6. Evaluation
Den Ergebnissen zufolge konnte man klare Unterschiede sehen bei den Algorithmen. Abhänged von der Netzwerk-Größe, war der CliZZ-Algorithmus der mit der schlechtesten Laufzeit. Bei verschiedenen Datensätzen derselben Größenordnung, brauchte der CliZZ besonders lange, wenn das Netzwerke entweder zu wenig oder zu viele Communities enthielt. Auch in den Visualisierungen ergibt sich bei dem CliZZ-Algorithmus keine eindeutige Einteilung in Communities. Die Farbverläufe der Knoten sind sehr mild und die Unterschiede lassen sich nur schwer erkennen.
Im Gegensatz dazu, hat sich der DMID-Algorithmus als besonders schnell und zuverlässig herausgestellt. Durch die Nutzung von “Dissasortative Mixing” gelingt es dem Algorithmus Communites auch in nicht so trivialen sozialen Netzwerken zu finden, wie z.B. bei der Wikipedia Voting. Außerdem liefert DMID für alle Datensätze gute und nachvollziehbare Ergebnisse.
Als dritter Algorithmus das getestet wurde, lieferte auch SLPA schwankende Ergebnisse, was aber mit seinem nicht-Determinismus zu tun hat. Dafür hielt sich seine Laufzeit aber im Rahmen. Die Besonderheit die uns bei SLPA aufgefallen ist, waren die sehr klaren und visuell schönen Ergebnisse, die eine sehr eindeutige Unterscheidung zwischen den Communities im Netzwerk erlauben.
Es muss auch bemerkt sein, das der einzige Algorithmus, speziell für gewichtete Netzwerke, nämlich der MONC-Algorithmus, eine extrem schlechte Laufzeit aufwies und auch eine Visualisierung war daher leider unmöglich, da der WebOCD Client überlasstet war, dafür wollen wir uns entschuldigen.
Außer den nicht klaren Unterschieden zwischen den Algorithmen, konnte man ziemlich klare Unterschiede zwischen den Datensätzen herausfinden.
Das Wikipedia Voting erwies sich als das Netzwerk mit den wenigsten Communities. Das klingt nachvollziehbar, da sich bei Wahlen, immer eine begrenzte Anzahl an Kandidaten finden, und somit auch nicht zu viele Communities entstehen können, wobei bei anderen Netzwerken wie z.B. Facebook, die Anzahl an sozialen Bekanntschaften bekanntlich unbegrenzt sein kann.
Anderensetis war Bitcoin-Alpha das Netzwerk mit den meisten Communities. Hier ist wohl zu bemerken, dass es sich um sehr viele kleine Communities gehandelt hat. Das klingt wieder verständlich, da es sich hierbei um Transaktionen von Währung handelt und sich bekanntlich nicht beliebige Menschen sich Geld überweisen.
Zu guter letzt war Facbook-TvShows, der Datensatz mit den meisten schankenden Ergebnissen. Das ist einerseits bedingt durch die Vielfalt der Film-Geschmäcker, aber anderenseits auch von den unterschiedlichen Herangehensweisen der Algorithmen.
7. Zusammenfassung
Die Ergebnisse der Algorithmen sind relativ gut und bestätigen was wir schon von den Datensätzen vermuten. Obwohl es bei der Größe der ausgewählten Datensätzen keinen sehr großen Unterschied gemacht hat, kann man jedoch vermuten, dass bei viel größeren Netzwerken die Benutzung von DMID sich am besten heraustellt.
Der DMID Algorithmus lieferte für alle Datensätze gute und nachvollziehbare Ergebnisse, und zudem war er auch sehr schnell. Jedoch konnte man generell keine starken Unterschiede zwischen den Algorithmen feststellen wenn es um die Anzahl gefundener Communities geht.
Grundlegend ist es wichtig bei der Analyse von Datensätzen auch ihre Herkunft in Betracht zu ziehen. Soziale Netzwerke gibt es zahlreiche und es entstehen immer wieder neue. Diese Arbeit hat sich nur auf eine kleine Anzahl von Netzwerken bezogen, jedoch konnte man schon bei einfachen Ansätzen starke und besondere Unterschiede bemerken abhängend von der “Genre” der Datensätze und des Netzwerks wo sie gesammelt wurden. Es bleibt noch viel Arbeit um bessere und effizientere Algorithmen zu entwickeln die in deren Implementierung auch die speziellen Eigenschaften der Netzwerke wo sie herstammen in Betracht ziehen und die uns dabei helfen werden gezielt in den einzelnen Bereichen so viel Ergebnisse wie möglich zu erhalten.
8. Referenzen
- Nerurkar, P., Chandane, M., & Bhirud, S. (2019). A Comparative Analysis of Community Detection Algorithms on Social Networks. In N. K. Verma & A. K. Ghosh (Eds.), Computational Intelligence: Theories, Applications and Future Directions - Volume I (Vol. 798, pp. 287–298). Springer Singapore. https://doi.org/10.1007/978-981-13-1132-1\textunderscore 23
- McAuley, J., & Leskovec, J. (2012). Learning to Discover Social Circles in Ego Networks. In F. Pereira, C. J. C. Burges, L. Bottou, & K. Q. Weinberger (Eds.), Advances in Neural Information Processing Systems 25 (NIPS 2012) (pp. 548–556).
- Kumar, Srijan and Spezzano, Francesca and Subrahmanian, VS and Faloutsos, Christos. Edge weight prediction in weighted signed networks. In Data Mining ICDM 2016 (pp. 221–230).
- Ryan A. Rossi and Nesreen K. Ahmed. The Nework Data Repository with Interactive Graph Analytics and Visualization. In AAAI 2015. https://networkrepository.com